This is an archival copy of the Visualization Group's web page 1998 to 2017. For current information, please vist our group's new web page.
Parallel Query-driven Analysis of Electron Linac Simulations
Problem Statement and Goals
Researcher of the Accelerator & Fusion Research Division at Lawrence Berkeley National Laboratory (LBNL) utilize large-scale, high-resolution simulations of beam dynamics in electron linacs for studies of a proposed next-generation x-ray free electron laser (FEL) at LBNL (external link). Particle-in-cell-based simulations of this type of accelerator require large numbers of macroparticles (> 108) to control the numerical macroparticle shot noise and to avoid overestimation of the microbunching instability, resulting in massive particle datasets. The sheer size of the data generated by these types of simulations poses significant challenges with respect to data I/O, storage, and analysis.Analysis and exploration of massive collections of scientific data is challenging, thereby, having a negative impact on the process of scientific discovery. In practice, gaining insights from scientific data often involves studying smaller regions or subsets of the data. Feature-based and query-driven data analysis methods have, therefore, gained much attention during the last decade. In this context, it is crucial that we are able to quickly and efficiently identify and access specific data subsets of interest. While this search problem has gained much attention in the database research community, most scientific data are not stored in database systems and are unable to take advantage of database indexing techniques. We require a general purpose state-of-the-art indexing and querying system that can process scientific data stored natively in formats such as HDF5 and NetCDF. In order for such a system to be applicable to massive datasets, it is critical that its design allows for execution on multi-core distributed memory platforms.
Implementation and Results
To enable analysis of large-scale, high-resolution particle accelerator simulations we need to address a large number of challenges, ranging from data I/O, to enable efficient data write and storage, to scalable index/query and visualization to support effective data analysis.I/O: To enable efficient I/O of massive particle datasets we use H5Part, a parallel HDF5-based data format, for data storage. We integrated H5Part with the IMPACT simulation suite, enabling for the first time high-performance parallel write and storage of the full particle data from large-scale, high-resolution IMPACT simulations. H5Part as a general, high-level HDF5-based data format and I/O library is well-integrated with modern visualization tools, including VisIt, enabling high-performance, parallel visualization and analysis of large-scale simulation data.
Scalable, High-performance Data Query: In collaboration with researchers of the SciDAC Scientific Data Management (SDM) Center, we designed FastQuery to accelerate queries on massive scientific datasets. FastQuery defines a general query/indexing API, linking FastBit indexing capabilities with standard scientific data formats (e.g, HDF5 and NetCDF). FastQuery also supports the indexing of subarrays of datasets. This subarray functionality allows us to perform data index and query operations in parallel on modern high-performance computing platforms with limited memory per-core. Previously, large shared-memory machines were usually needed to create monolithic indices of massive scientific dataset. Using subarrays, data queries can be evaluated in a massively parallel fashion, thereby dramatically improving the applicability and performance of the system. Integration of modern index/query technologies with the visualization system VisIt enable the analysis of massive particle datasets, which would otherwise be impractical.
Visualization: In this work we use the high-performance, parallel visualization system VisIt, for parallel visualization of the complete, as well as subsets, of the particle data. We have integrated H5Part and FastBit with VisIt which enables us to perform data query operations directly at the file reader stage of the visualization pipeline, thereby, reducing the amount of data that needs to be transfered to and processed by the visualization algorithms.
This work is described in more detail in a SC11 conference paper by Chou et al. [1]. Recent extensions of this work to study extreme-scale output from magnetic reconnection simulations have been described in a SC12 paper by Byna et al. [2].
Results
Query-based data analysis as a general analysis tool has a wide range
of applications, e.g., analysis of extremely large computer
network traffic data and data from laser wakefield particle
accelerator simulations. In context of linacs, query-based analyses are
useful for defining beam diagnostics based on the analyses of
characteristic subparts of the beam, e.g., the transverse halo and core
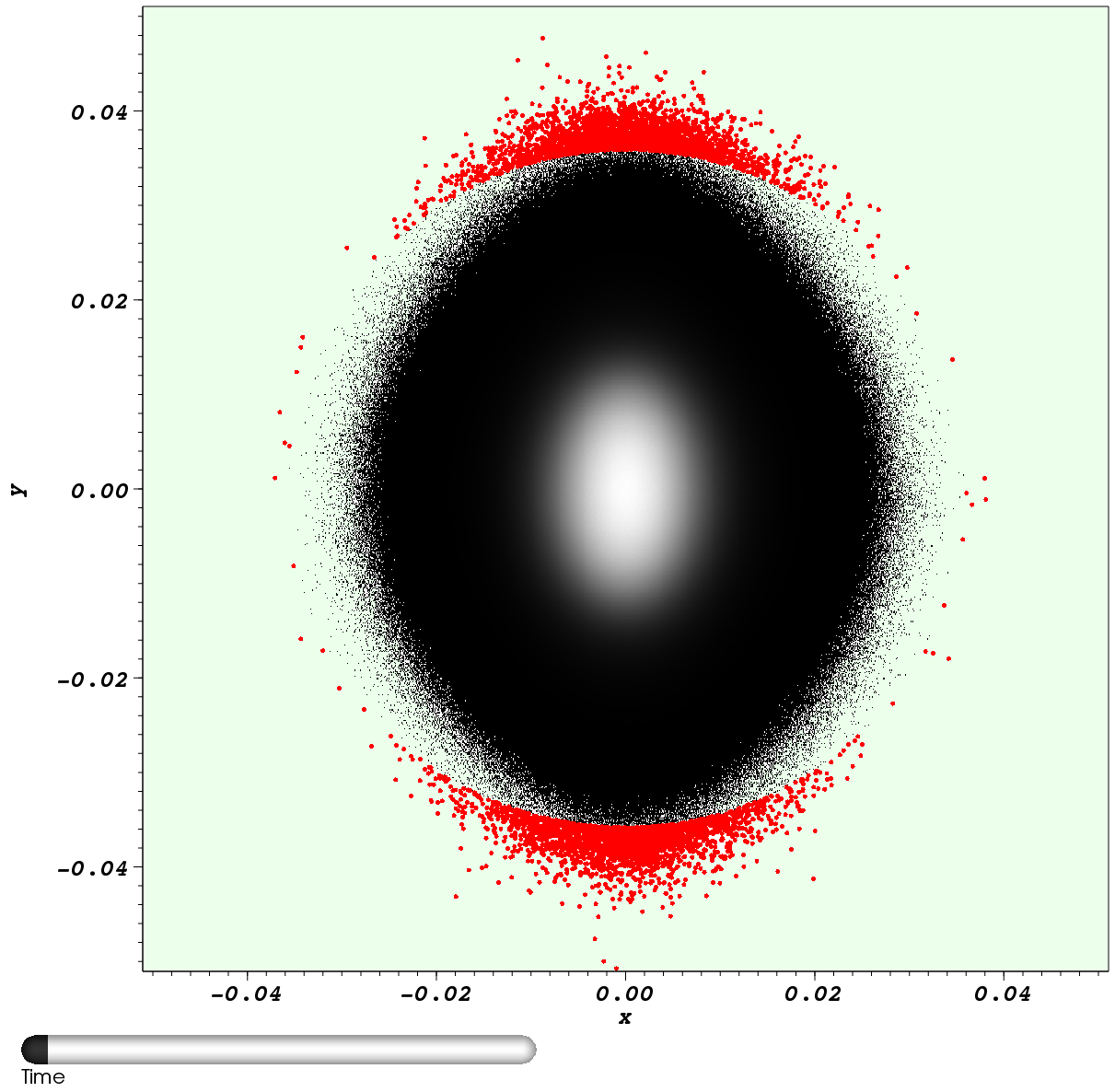
of the beam. The transverse halo of a particle beam is a low density
portion of the beam usually defined as those particles beyond some
specified radius or transverse amplitude in physical space (see Figure
1a). Particles in the halo have the potential to reach very large
transverse amplitude, eventually striking the beam pipe and causing
radioactivation of accelerator components and possibly causing
component damage. Controlling the beam halo is critical to many
accelerator facilities and is often the limiting factor to increasing
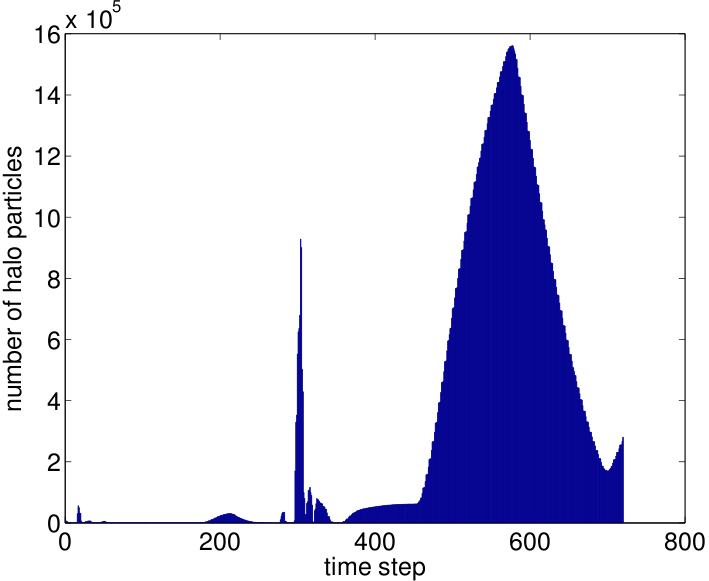
the beam intensity to support scientific experiments.Figure 1b shows the number of particles selected by the halo query for each timestep For the halo query we observe large variations in the number of particles that satisfy the query. The larger numbers of halo particles at late timesteps provide impetus to explore the source of the halo. In this case the halo particles
and the observation of an increase in the maximum particle amplitude were found to be due to a mismatch in the beam as it travels from one section of the accelerator to the next. These diagnostics provide accelerator designers with evidence that further improvement of the design may be possible, and they provide quantitative information useful for optimizing the design to reduce halo formation and beam interception with the beam pipe, and ultimately to improve accelerator performance.
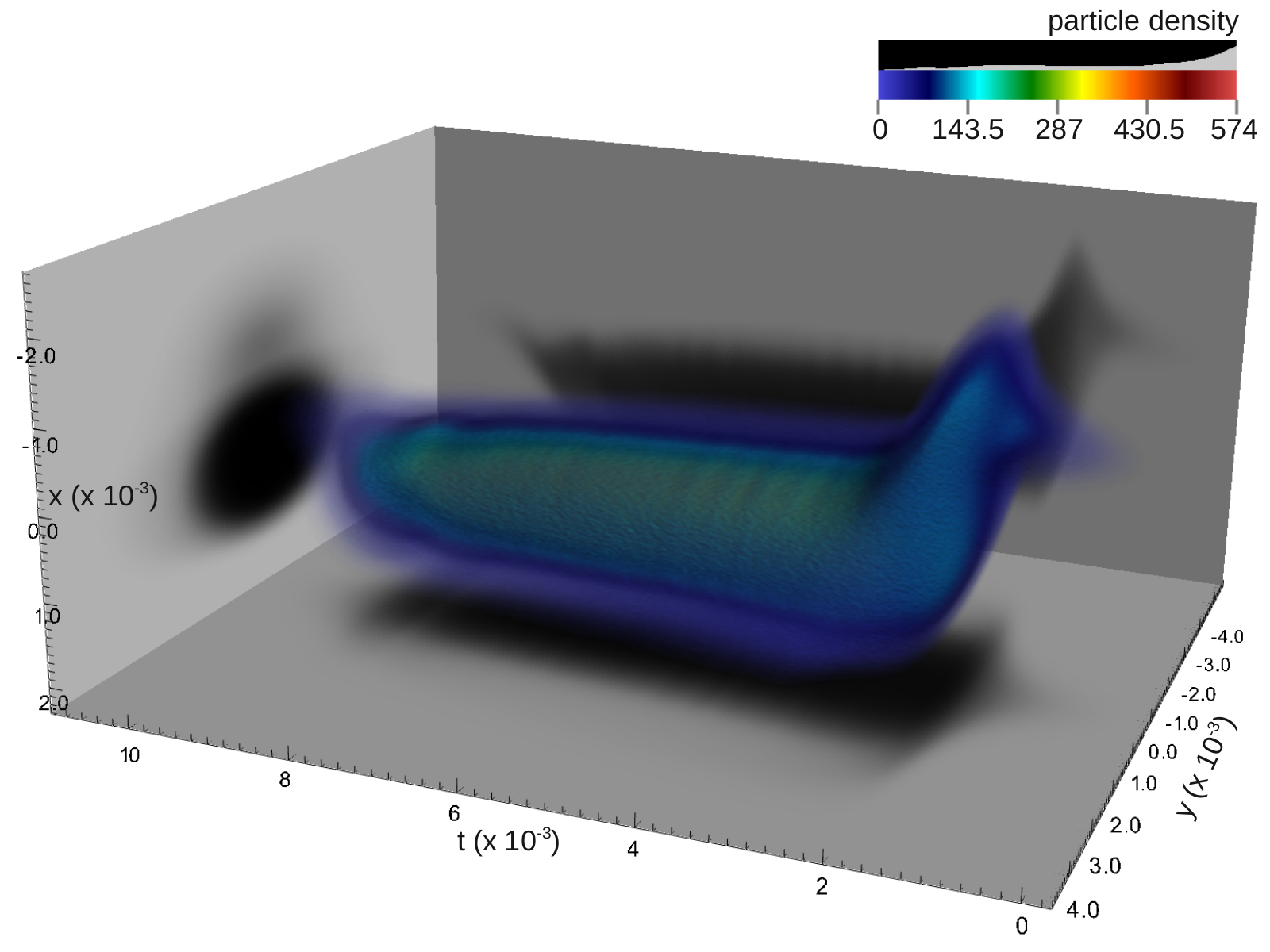
Figure 2 also demonstrates the application of VisIt used to visualize the complete particle data in 3D. Utilizing advanced parallel visualization capabilities enables scientist to efficiently analyze the three-dimensional structure of the particle beam in physical space (see Figure 2a) and to compute standard beam diagnostics (see Figure 2b) for extremely large particle datasets.
 |
 |
| (a) Example halo query for t=20 |
(b) Number of halo particles per timestep |
| Figure
1: Halo query analysis results. (a) Particle density plot (gray) and
particles selected (red) by the halo query for timestep 20 of the
simulation. (b) Number of halo particles per timestep. |
|
 |
 |
| (a) Particle density in physical space at timestep 1285. | Particle density in (t,pt) phase space at timestep 1285. |
| Figure
2: Application of the parallel visualization system VisIt for the
analysis of large particle beams. (a) Volume rendering of the particle
density in physical space at a late timestep of simulation illustrating
the shape of the beam and distribution of beam particles. (b) Surface visualization of a 2D histogram of (t,pt) space. |
|
Impact
Integration of the H5Part file format API and library with the IMPACT simulation suite enables for the first time high-performance parallel write and storage of the full particle data from large-scale, high-resolution IMPACT simulations.Making state-of-the-art, high-performance, distributed, index and query technology accessible to a large range of scientific data formats (such as, H5Part, HDF5 or NetCDF), is critical for a large range of feature-based and query-driven analysis methods. The integration of H5Part and modern query technologies with the visualization enables interactive and repeated, complex, large-scale query-based analysis of massive datasets, which would otherwise be impractical with respect to both time as well as computational cost. In this work we have demonstrated that using this query-driven approach provides effective means for efficiently computing particle beam diagnostics. Using the high-performance, parallel visualization system VisIt enables us for the first time to perform efficient 3D visualization of the full article data.
References
[1] Jerry Chou, Kesheng Wu, Oliver Rübel, Mark Howison, Ji Qiang, Prabhat, Brian Austin, E. Wes Bethel, Rob D. Ryne, and Arie Shoshani. Parallel Index and Query for Large Scale Data Analysis. In Proceedings of Supercomputing 2011, Seattle, WA, USA, 2011. LBNL-5317E. (PDF) (BibTeX)[2] Surendra Byna, Jerry Chou, Oliver Rübel, Prabhat, Homa Karimabadi, William S. Daughton, Vadim Roytershteyn, E. Wes Bethel, Mark Howison, Ke-Jou Hsu, Kuan-Wu Lin, Arie Shoshani, Andrew Uselton, and Kesheng Wu, "Parallel I.O, Analysis, and Visualization of a Trillion Particle Simulation," SuperComputing 2012 (SC12), Salt Lake City, Utah, Nov. 10-16, 2012. LBNL-5832E. (BibTeX)(PDF - coming soon) (This article was also featured in the following news releases: i) Linda Via, "Sifting Through a Trillion Electrons: Berkeley researchers design strategies for extracting interesting data from massive scientific datasets," June 26, 2012. [Online at crd.lbl.gov and nersc.gov] and ii) Today At Berkeley Lab, "NERSC Users Generate a Quickest-Ever, 32-Terabyte 3D Simulation," June 27,2012. )