This is an archival copy of the Visualization Group's web page 1998 to 2017. For current information, please vist our group's new web page.
Global Cloud Resolving Model Simulations
 |
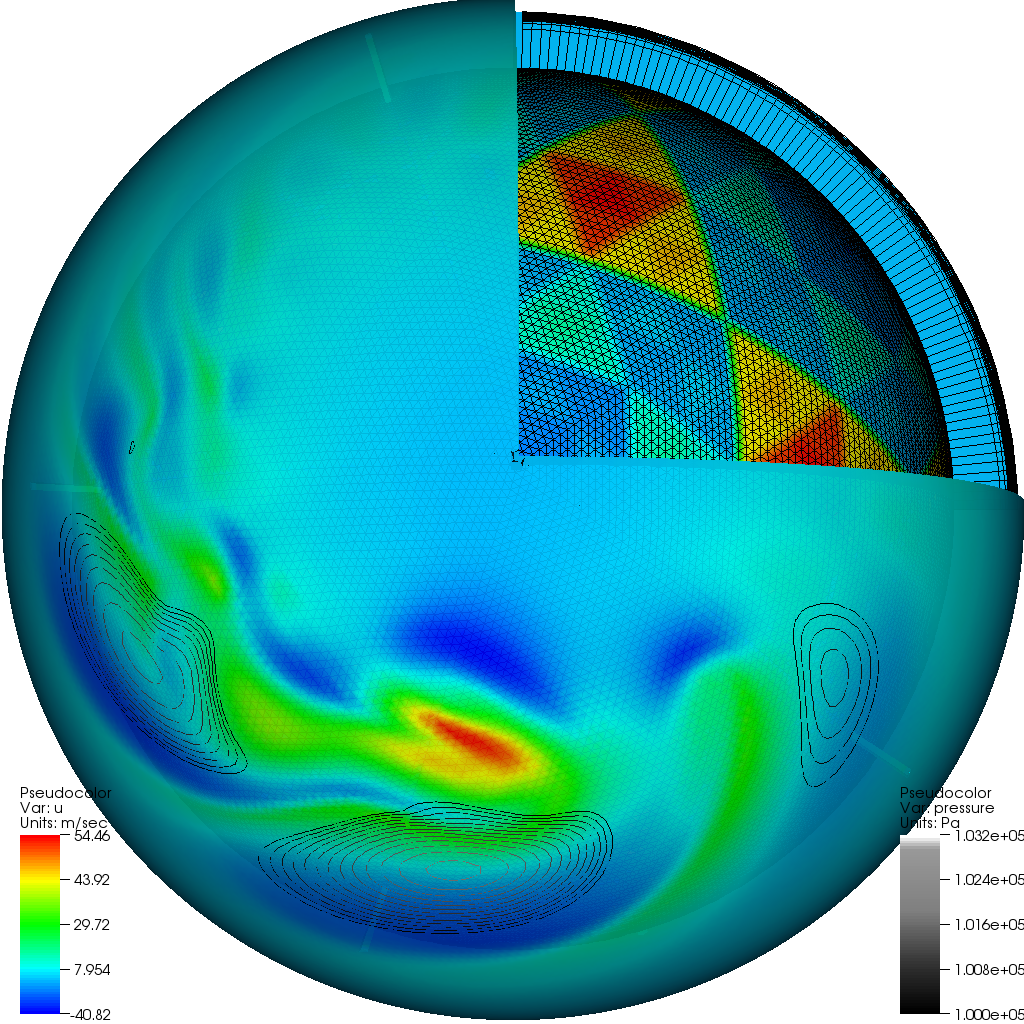 |
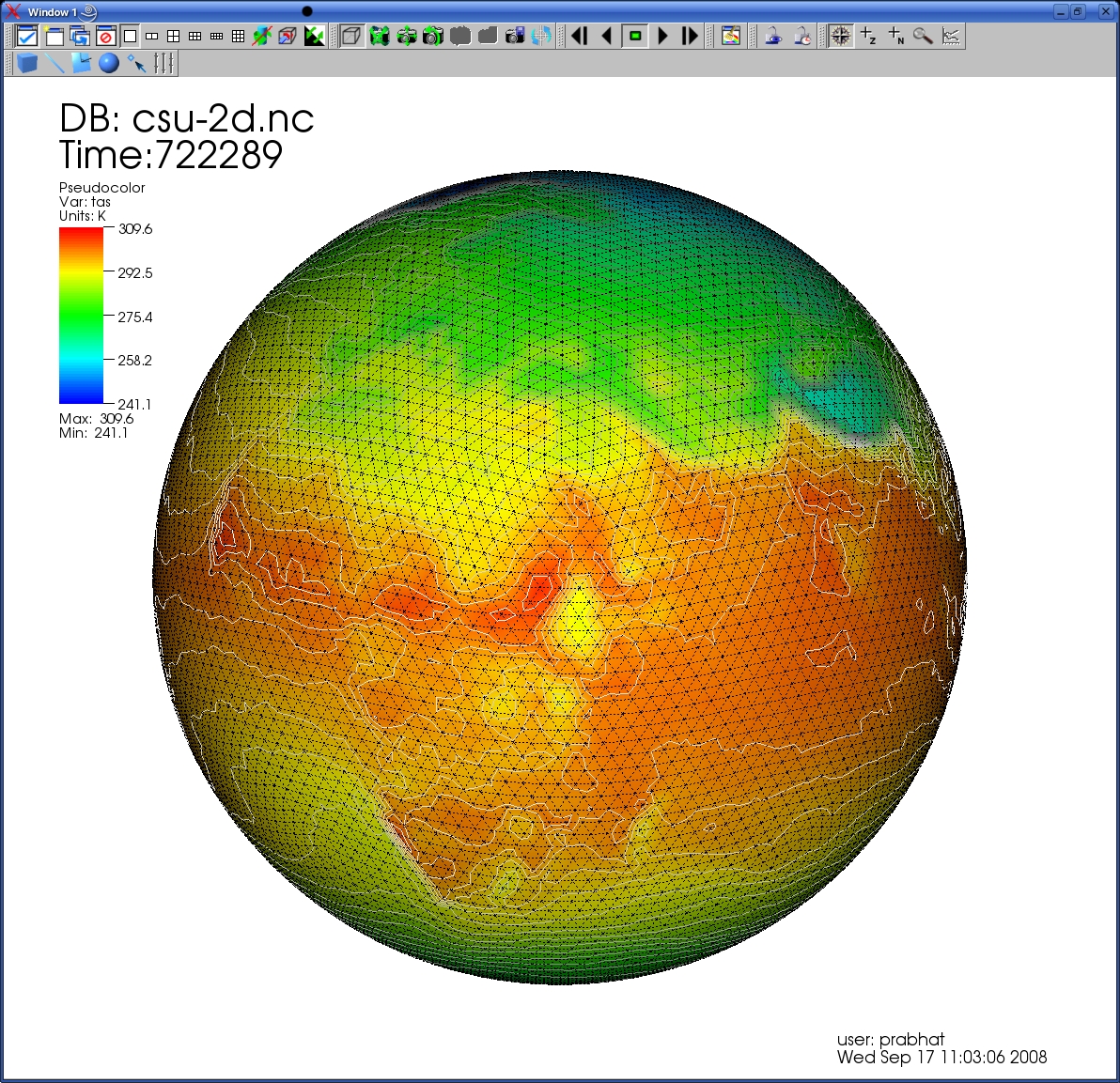
| Plot of surface temperature and the geodesic cells. | Composite plot of multiple mesh types and variables. |
Scientists at Colorado State University led by Dave Randall have developed a Global Cloud Resolving Model (GCRM) that runs at extremely fine resolutions (on the order of 1km) to accurately simulate cloud formation and dynamics. Underlying this simulation is a geodesic grid data structure containing nearly 10 billion total grid cells, a unprecedented scale that challenges existing I/O and visualization strategies.
In collaboration with PNNL researchers, we have developed a data model for the variables associated with geodesic grids: cell-centered, corner-centered and edge-centered data. The current data model is implemented in NetCDF. The extreme scale of these datasets make them challenging to load into analysis and visualization programs. We have developed both serial and parallel plugins for loading geodesic grid data into VisIt, a richly featured parallel visualization platform. The preliminary visualizations shown above were created using this plugin.
We have worked jointly with PNNL researchers and Cray and NERSC personnel to troubleshoot and tune collective I/O operations to shared files on Franklin, NERSC's flagship Cray XT4 system. Through a number of tests, we identified inefficiencies in Cray's implementation of collective buffering in the XT4's MPI-IO library. Franklin uses the lustre parallel filesystem, which stripes large shared files over a user-specified number of backend I/O servers. The default stripe width is 4MB, and writes to the file that do not align to the stripe boundaries cause locking contention as lustre attempts to provide a coherent view of the file. Based on our analysis, Cray revised their collective buffering algorithm to issue write calls that respect the stripe boundaries. With these improvements, we can obtain collective write bandwidths on the order of several GB/s, close to the theoretical peak.
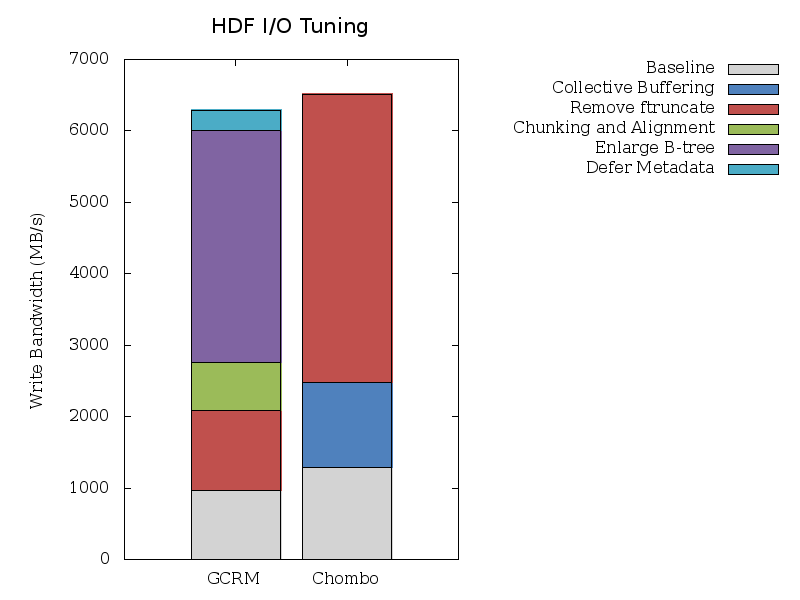
Additionally, we have optimized an I/O pattern in HDF5 for the GCRM data model. By using HDF5's chunking mechanism, we are able to linearize the pattern so that the filesystem's view of a dataset is contiguous. Combined with a reduced subset of writers (2-phase I/O), stripe alignment, and metadata aggregation we can achieve high write bandwidths on Franklin (see the graph below). This work is part of an ongoing collaboration between NERSC Analytics / Advanced Technology Group and the HDF Group.
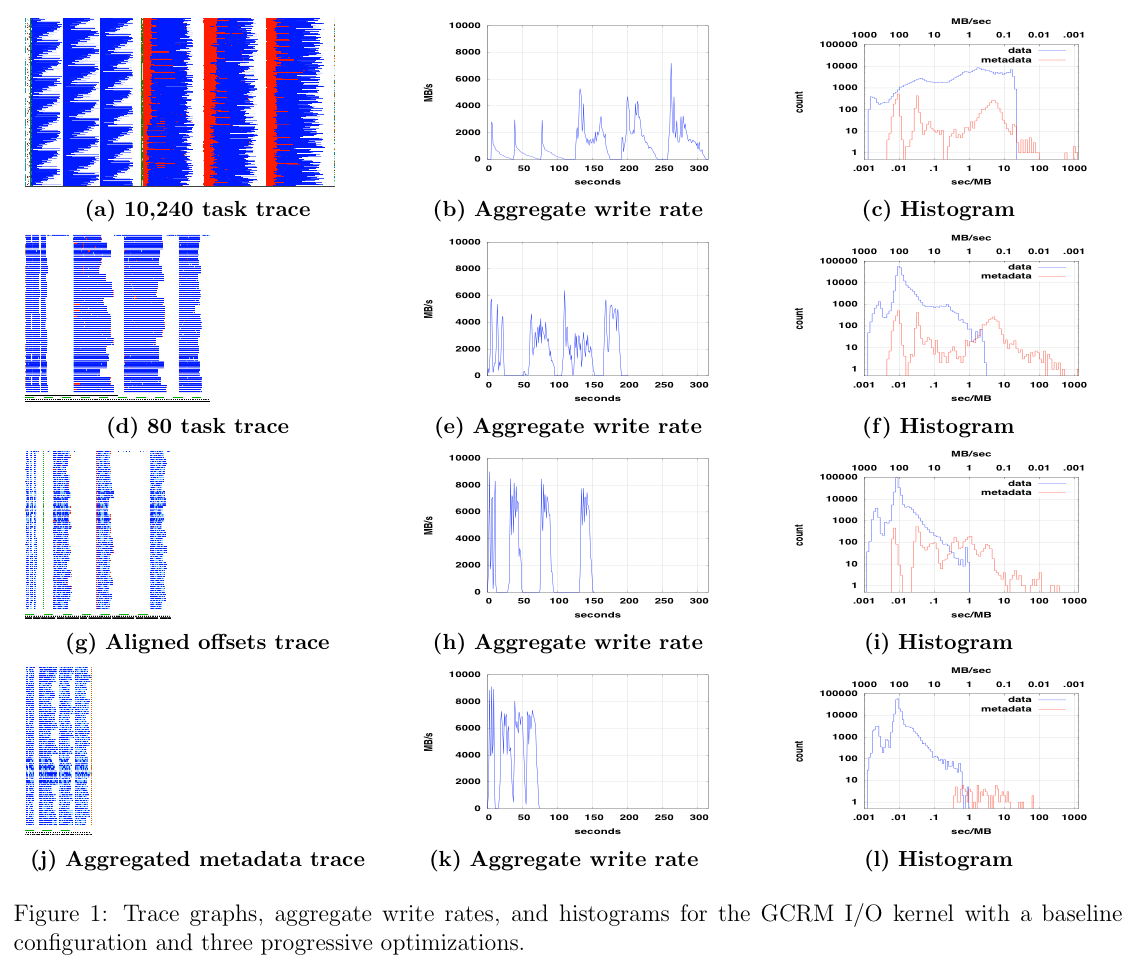
Our I/O analysis has benefited from a I/O tracing we have conducted with a development version of the Integrated Performance Monitor (see below). These traces provided a detailed view of individual nodes' I/O performance and individual I/O operations.
Collaborators
- Dave Randall
- Ross Heikes
- Karen Schuchardt
- Bruce Palmer
- Annette Koontz
Media