This is an archival copy of the Visualization Group's web page 1998 to 2017. For current information, please vist our group's new web page.
Hybrid Parallelism for Volume Rendering at Large Scale
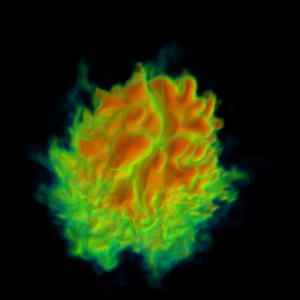
This 46082 image of a combustion simulation result was rendered by our MPI+pthreads implementation running on 216,000 cores of the JaguarPF supercomputer. [hi-res 4.2MB image]
{kind=link}
Supercomputing trends point toward greater and greater numbers of cores per node. While four to eight cores per node are common today, future supercomputers are likely to have hundreds to thousands of cores per node, and possibly as much as one billion cores total. This architecture suggests an opportunity for hybrid parallelism, where distributed memory parallel techniques are used across nodes, but shared memory parallel techniques are used within the nodes. For this study, we wanted to explore a canonical visualization algorithm, volume rendering, in the hybrid parallel space. Our research questions were:
- Is it viable to do volume rendering in a hybrid parallel setting? How should the volume rendering algorithm be mapped onto an architecture of multiple nodes each with multiple cores?
- Can we improve performance using hybrid parallelism? How and why?
- When going to extreme scale, can we observe indicators that a distributed memory only approach will not be viable on future machines?
To answer these questions, we implemented a volume renderer that could run in three modes: MPI-only, which employed distributed memory parallel techniques and ignored the possible benefits of shared memory within a node, MPI+pthreads, which had one MPI task per node and ran pthreads to get shared memory parallelism within a node, and MPI+OpenMP, which was similar to MPI+pthreads, but used OpenMP instead of pthreads. Our test system was JaguarPF, a Cray XT5 located at Oak Ridge National Lab that was recently ranked by the Top500 list as the fastest supercomputer in the world with a theoretical peak performance of 2.3 Petaflops. Comprised of dual-socket nodes with six-core processors and 16GB of memory, JaguarPF has 224,256 available compute cores. We conducted a strong scaling study where we rendered a 46082 image from a 46083 dataset (roughly 97.8 billion cells) at concurrency levels from 1,728-way parallel to 216,000-way parallel. In the hybrid case, we shared a data block among six threads and used one sixth as many MPI tasks.
Our experiments showed that the hybrid-parallel implementations (both MPI+pthreads and MPI+OpenMP) demonstrated similar gains over the MPI-Only implementation across a wide range of concurrency levels; the hybrid-parallel implementations ran faster, required less memory, and consumed less communication bandwidth. The volume rendering algorithm consists of two broad phases: ray casting, where the volume is intersected along rays, and compositing, where the resulting intersections are exchanged among the nodes and the final image is assembled. The ray casting phase, which is embarrassingly parallel, exhibited near-linear scaling all the way up to 216,000 cores. The compositing phase, whose performance is heavily dependent on communication time, was faster for the hybrid algorithms because there were less participants (one sixth as many) and fewer messages to communicate. At 216,000 cores, the best compositing time for MPI-hybrid (0.35s, 4500 compositors) was 67% less than for MPI-only (1.06s, 6750 compositors). Furthermore, at this scale compositing time dominated raycasting time, which was only 0.2s for both MPI-only and MPI-hybrid. Thus, the total volume rendering time was 55% faster for MPI-hybrid (0.56s versus 1.25s). Overall, the scaling study showed that MPI-hybrid outperformed MPI-only at every concurrency and that the margin of improvement became greater as the number of cores increased.
These results helped to answer our research questions: volume rendering is viable in a hybrid parallel setting and hybrid parallelism can improve performance, primarily in the compositing phase, and especially at extreme concurrency with an algorithm that minimizes the number of MPI tasks. Further, although we did not expect to see much in terms of indicators that a pure distributed memory parallelism would not be viable, we were surprised to find that simply initializing MPI with 216,000 tasks consumed over two gigabytes of memory per node, which is one eighth of the total memory on the machine. For the hybrid implementation, which had one sixth as many MPI tasks, less than one tenth of the memory was required to do the same initialization.
Related Publications
M. Howison, E.W. Bethel, & H. Childs. MPI-hybrid Parallelism for Volume Rendering on Large, Multi-core Systems. Eurographics Symposium on Parallel Graphics and Visualization, May, 2010. [Best paper award] [PDF]