This is an archival copy of the Visualization Group's web page 1998 to 2017. For current information, please vist our group's new web page.
Query-Driven Analysis of Large Scale Time-dependent Data
Problem Statement and Goals
Query-driven analysis based on single timestep queries is a versatile tool for the identification and extraction of temporally persistent and instantaneous data features. Temporal tracking and refinement of selections based on information from multiple timesteps then supports detailed analysis of the temporal evolution of data features. Many questions of interest ---such as, which particles become accelerated, which locations exhibit high velocities during an extended timeframe, which particles reach a local maximum energy, or which particles change their state--- inherently depend on information from multiple timesteps and cannot directly answered based on single-timestep queries alone. The goal of this effort is to extend our query-driven analysis capabilities to enable scientists to formulate time-dependent queries that accumulate information from multiple timesteps, here called cumulative queries.Implementation and Results
Cumulative queries extend the concept of query-driven analysis---which is based on the evaluation of queries at single timesteps---to incorporate information from the complete time-series. Cumulative queries are a versatile and flexible tool for identifying temporal features that cannot be identified based on information from individual discrete timesteps. Similar to the results of a single timestep query, the results of a cumulative query can be used directly for data selection by applying a boolean operator to change the counts of how often a particular data record matches the query into a true or false.While such primary cumulative queries are important, there is a significant amount of information that can be further mined by refining cumulative query results via secondary queries. Secondary queries can be based on multiple criteria to: i) select records that match the primary query most or least frequently, ii) select only records that match the primary query within a given time frame or at timesteps with a particularly high or low number of matches, or iii) refine the query based on information of data values that have not been used in query but which show interesting trends with respect to the data subset retrieved by the query.
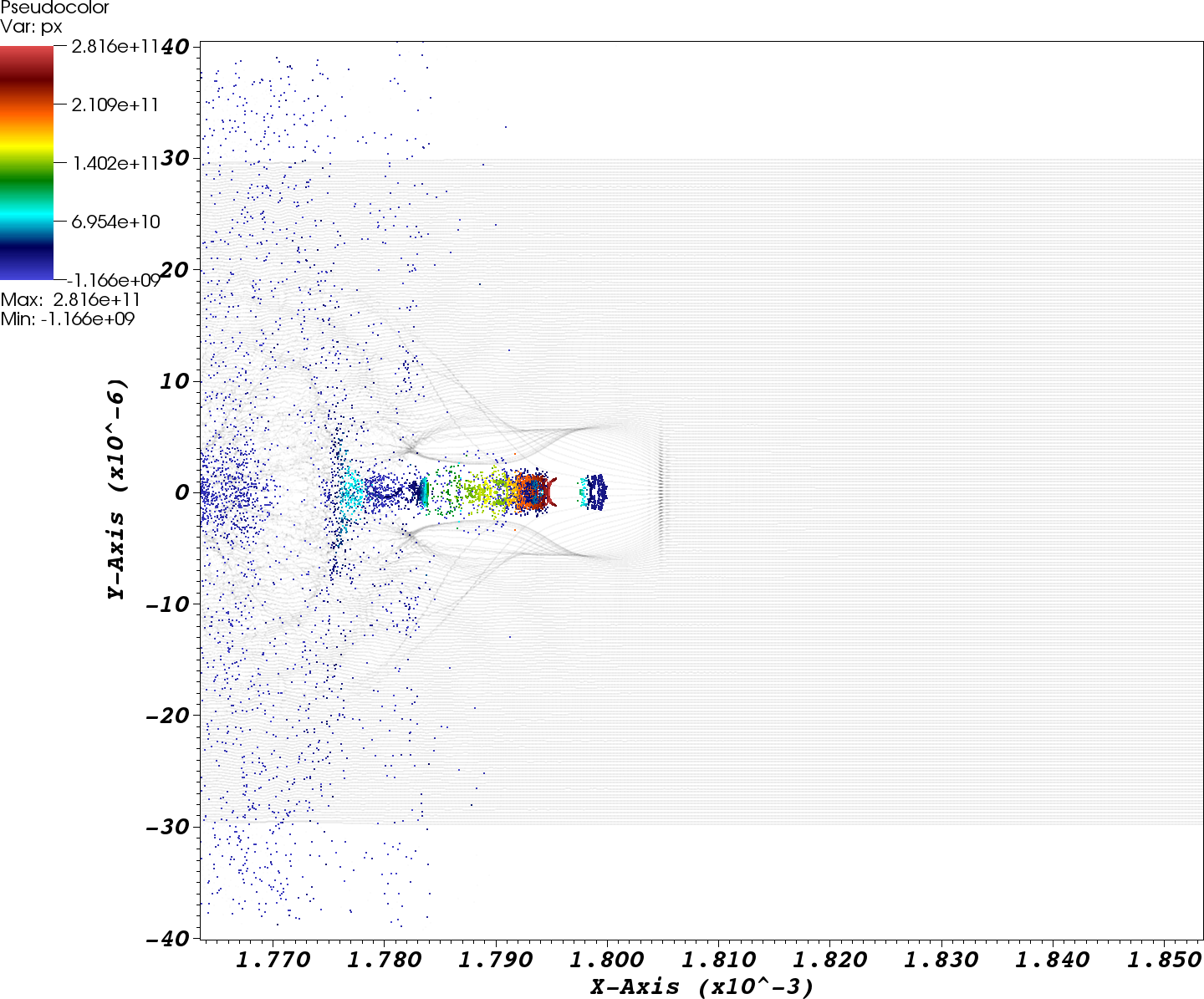
As an example use case, Figures 1 and 2 illustrate the application of cumulative queries for analysis of laser plasma particle accelerator (LPA) simulation data. Figure~\ref{fig:cumQuery1} shows the results of the primary cumulative query of px>1010, which allows us to identify all particles that have become accelerated to high energy levels at some point during the course of the simulation (see Figure 1). By applying a secondary query condition, we can then identify the subset of particles that are accelerated for a long period of time (see Figure 2).
As in the LPA example shown here, a basic cumulative query is typically based on intra-timestep queries---i.e., the basic query is evaluated independently for all timesteps and depends only on information from the given timestep. In some cases---e.g., when investigating changes of state between timesteps---the base query itself relies on information from multiple timesteps (inter-timestep query). To evaluate such inter-timestep queries we typically first compute a derived quantity, to describe, for example, in the case of fusion simulations, whether a particle is trapped or not. This allows us to translate inter-timestep queries into sets of queries that can be evaluated independently on a per timestep basis.
This work is presented in more detail in a 2012 EuroVA paper by A. Sanderson et al. [1]
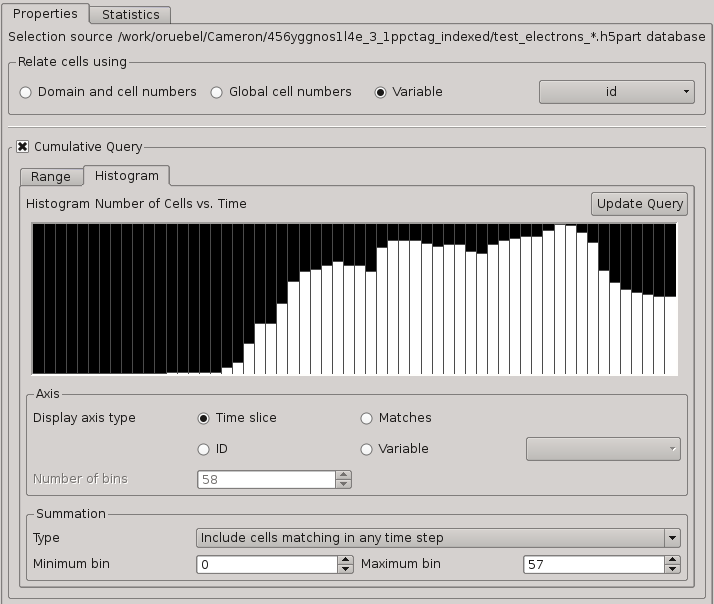 |
 |
| (a) Cumulative query GUI showing a histogram of the number of particles that suffice the query condition of px(t)>1010 at each timestep. |
(b) Visualization of the selected particles colored by px and all particles (gray) shown at timestep t=37. |
| Figure
1: Cumulative query over time selecting all particles exceeding a threshold of px>1010
in the momentum in acceleration direction x at least once during the
complete timeseries. The histogram shown in (a) reveals the initial
timeframe of injection and acceleration (increase in the number of
particles). The visualization shown in Figure (b) shows the location of
the energetic particles in physical space. |
|
 |
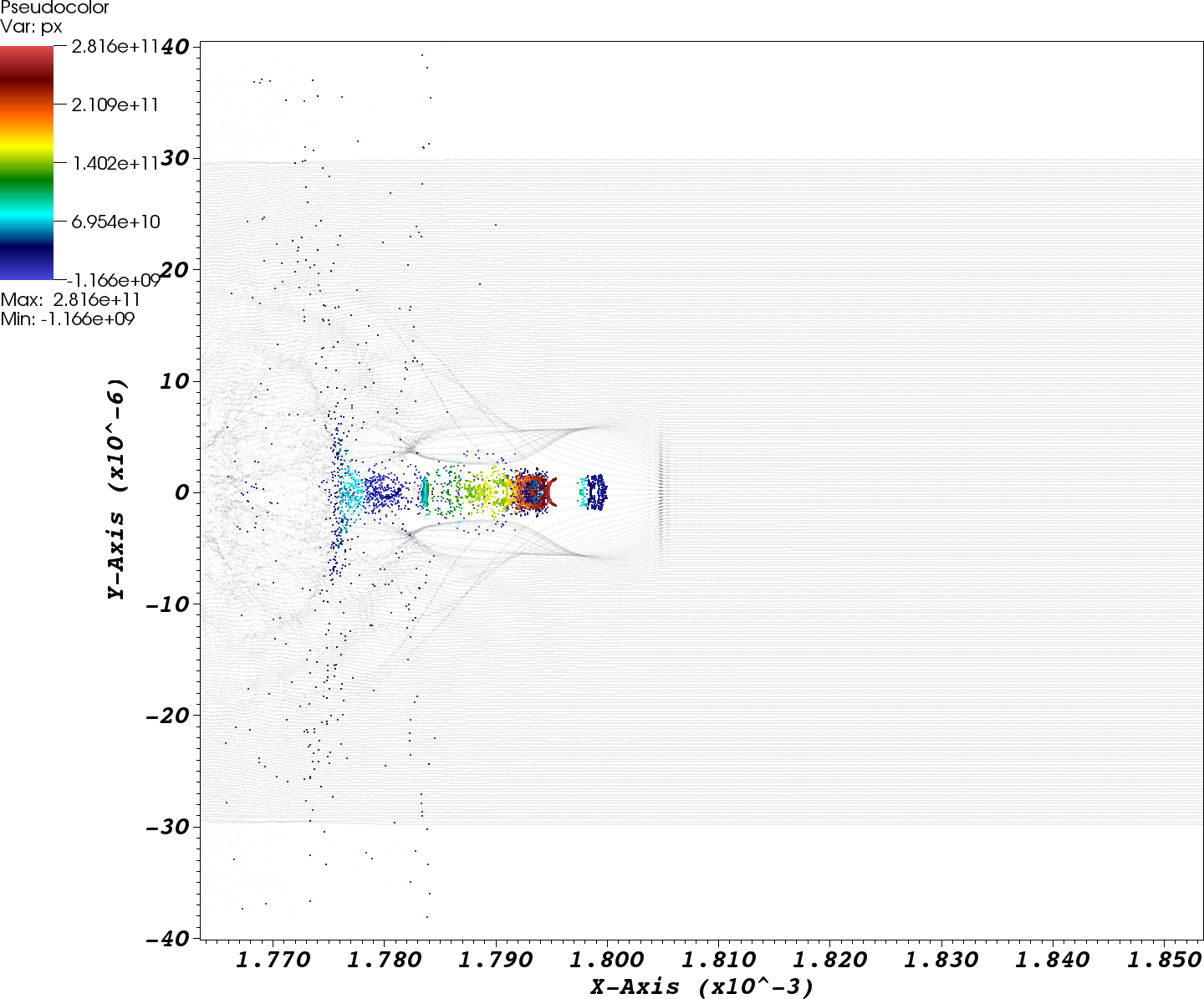 |
| (a) Cumulative query GUI showing a histogram of the number of times particles matched the query condition of px(t)>1010 | (b) Visualization of the selected particles colored by px and all particles (gray) shown at timestep t=37. |
| Figure
2: Using a secondary query allows us to select only those particles
that are accelerated for a long period of time by selecting only those
particles which match the query condition at at least 24 timesteps.
Figure (b) again shows the spatial locations of the particles that
match the refined query (compare also with Figure 1b) |
|
Impact
Cumulative queries provide intuitive and effective means for application scientists to investigate complex, time-dependent hypotheses and questions that cannot be easily addressed using singe timestep queries. Cumulative queries are a general tool with a wide range of applications in sciences that require the study of time-varying data. Many important questions in accelerator, fusion or combustion research, and many other science applications, inherently depend on information from the complete time-series---e.g., which particles become accelerated, which particles switch state from trapped to untrapped and many others. Investigations for these types of questions are fundamentally important and in many cases form the foundation for further detailed studies of the data portions of interest identified via cumulative queries. For example, we have developed automatic beam detection analyses that utilize cumulative queries to: i) identify all particles that become accelerated (intra-timestep query), and toii) identify particles with a local maximum in energy (inter-timestep query). We have deployed cumulative query capabilities in the high-performance parallel visualization system VisIt.