This is an archival copy of the Visualization Group's web page 1998 to 2017. For current information, please vist our group's new web page.
Evaluating the Benefits of an Extended Memory Hierarchy for Parallel Streamline Algorithms
|
|

|
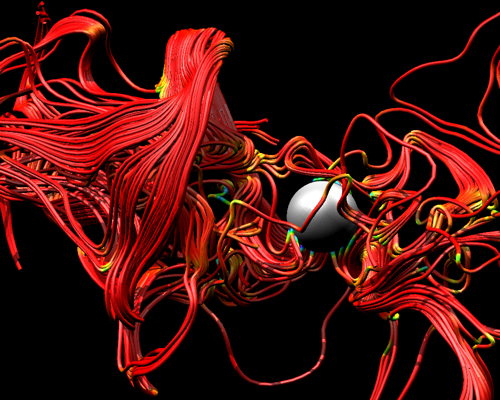
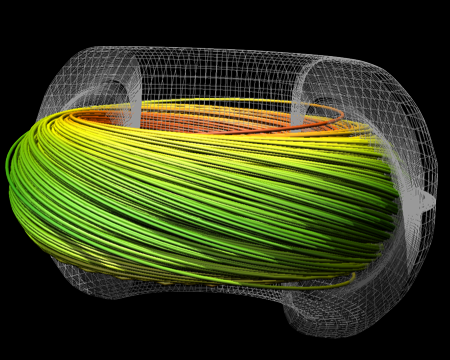
| Figure 1. Our performance study uses datasets from three scientific disciplines: astrophysics, fusion, thermal hydraulics (left to right). Since the performance of the streamlines algorithm is highly dependent upon initial seed placement and the flow field through which streamlines are computed, using three very different datasets helps to ensure our performance study does not include any dataset-specific bias. | ||
Problem Statement and Goals
I/O performance is an increasing performance bottleneck for many high performance applications as the gap widens between our ability to perform computations and write the results to permanent storage, This performance bottleneck is especially prevalent when parallel simulations perform checkpointing, which is the process of writing the entire contents of memory to disk. When such writes occur, the simulation stops computing and remains blocked waiting for this potentially expensive I/O operation to complete.
In an effort to minimize the impact of relatively slow I/O performance on simulations, computer architects have been experimenting with alternative I/O system architectures with an eye towards improving overall I/O performance. An example of one approach uses a two-stage I/O system: a remote parallel file system coupled with locally attached storage in the form of either traditional hard disk drives (HDDs) or solid state drives (SSDs). The idea is that the simulation writes to the I/O subsystem, which traditionally goes to the higher latency and slower conventional filesystem, are instead routed to lower latency (faster), locally attached storage, so as to minimize the amount of time simulations are blocked waiting on I/O. In the two-stage architecture, data is migrated transparently to the simulation from locally attached storage to the conventional filesystem. Although locally attached storage devices could be viewed as adding a new monetary cost to the overall system price, they provide a much reduced latency, which in turn produces better I/O performance, therefore lessening the importance of absolute I/O latency and bandwidth of the conventional filesystem. System designers have the option of using a lower-cost conventional filesystem, thereby resulting in an overall lower cost for a better performing, two-stage I/O subsystem.
While this two-stage, locally attached storage design was originally intended to accelerate write performance for scientific simulations, an open question is whether this two-stage architecture can benefit read-mostly data intensive applications, like visualization and analysis.
Implementation and Results
|
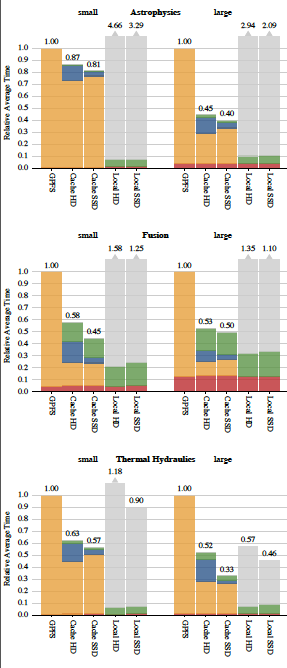
| Figure 2. Using the local storage as a cache (Cache HD, Cache SSD) results in up to about a two-fold improvement in performance compared to baseline performance (GPFS). When the entire dataset can fit into local storage, performance is better (Local HD, Local SSD) but requires an expensive one-time data copy (shown in gray). |
We conducted studies aimed to better understand the degree to which locally attached storage, either in the form of HDDs or SSDs, can accelerate the performance of a read-oriented data-intensive algorithm, namely streamline calculations, on distributed-memory parallel platforms. Our approach centers around the idea of considering the locally attached storage as part of an extended memory hierarchy, rather than a two-stage I/O system where data migration between different layers occurs transparently to the application. While the first read of any data block data will require retrieving data from the conventional filesystem, subsequent reads of the same data block could be serviced by locally attached storage, resulting in potentially better overall I/O performance.
We study the streamlines computation algorithm in this context because it can be highly read intensive, as different instances of the parallel application can potentially perform redundant read operations. In the parallelize-over-seeds approach to streamline calculation, each processor is responsible for computing streamlines given a set of seed points. As the computation proceeds, the streamline will exit one block of data and enter another, which in turn results in a data read operation. If the streamline exits a block of data only to enter it later, then that data needs to be read again, resulting in a redundant read. The idea is to reduce the amount of time required to complete these redundant reads by having the read request serviced by a local data cache, rather than the conventional filesystem.
To best understand the performance characteristics of a parallelize-over-seeds streamline algorithm with an extended memory hierarchy, our methodology tests various aspects of algorithm performance in a variety of conditions that include different I/O configurations (e.g., with and without locally attached storage) as well as different scientific datasets since the performance of the streamline algorithm depends on the placement of seed points as well as the flow field being studied.
In the first I/O configuration, which we denote GPFS, each MPI task loads data blocks directly from the general parallel file system (GPFS), establishing a baseline for performance without an extended memory hierarchy. In the second I/O configuration, Cache SSD, each MPI task can load data blocks from either the SSD or from the GPFS. For each load, the task starts by checking whether the data block is resident in the application managed cache on the SSD. If the SSD does not contain the data, then the task loads the block from the GPFS and stores the data block in the data cache on the SSD, so that subsequent loads of that block will come from the faster SSD. The fourth and fifth I/O configurations, Cache HD and Local HD, are identical to the second and third I/O configurations, except that the locally attached storage is a hard drive rather than a solid-state drive.
Our study used data sets from three different scientific domains---fusion, thermal hydraulics, and astrophysics---to provide a range of coverage in the different types of vector fields. Example output showing streamlines in all three datasets is shown in Figure 1. The fusion data set is from a simulation of magnetically confined fusion in a tokamak device. The thermal hydraulics data set is from a problem where twin inlets pump air into a box, and there exists a temperature difference between the two inlets. The astrophysics data set was created from a simulation of the magnetic field surrounding a solar core collapse resulting in a supernova. For each data set, we used two seeding set sizes: a small seed set containing 2,500 seed points and a large seed set containing 10,000 seed points.
Figure 2 shows a summary of the results from this study. The configuration for baseline I/O performance configuration uses reads coming from the GPFS, and without any locally attached storage. The baseline performance value is shown as 1.0 in these charts. Performance values of other configurations are normalized to that baseline. Values less than 1.0 are faster than the baseline performance, and show that using the local SSD or HDD as a local cache improves performance in all problem configurations. This result is due to the fact that data reloads can be serviced by faster, local storage rather than slower, distant storage. Problem configurations that fit entirely within local storage (Local HD and Local SSD) are much faster than the GPFS configuration, but require an expensive one-time data copy, which is labeled (or depicted) by the gray columns in Figure 2. The results of this study show that use of locally attached storage and an application managed data cache produced an overall speedup of approximately 100%.
This work is described in more detail in the Proceedings of the IEEE Symposium on Large-Scale Data Analysis and Visualization (LDAV) 2011 [1].
Impact
Our study shows that using an advanced architectural configuration, namely locally attached storage comprised of low-cost SSDs, can accelerate performance of a read-oriented, data-intensive algorithm by a factor of two across a diverse set of problem configurations. Our experiments were designed to test different aspects of performance, which in turn yield insights about different architectural configurations. Our results showed that an architecture originally intended to accelerate performance of write-intensive applications (e.g., simulations) can also benefit read-intensive applications (e.g., streamlines calculation).
References
[1] David Camp, Hank Childs, Amit Chourasia, Christoph Garth, and Kenneth I. Joy. Evaluating the Benets of An Extended Memory Hierarchy for Parallel Streamline Algorithms. In Proceedings of the IEEE Symposium on Large-Scale Data Analysis and Visualization (LDAV). IEEE Press. October, 2011. LBNL-5503E.