AMR (Adaptive Mesh Refinement) is a technique to speed up large-scale PDE simulations. Instead of resolving the domain of the simulation problem as a single uniform grid, the simulation runs on a hierarchy of grids of different cell sizes. This way, a grid can be locally refined only where the PDE solver requires high resolution, and can use coarse resolution otherwise, see Figure 1.
| |
| Figure 1: An example (2D) AMR data set. |
|---|
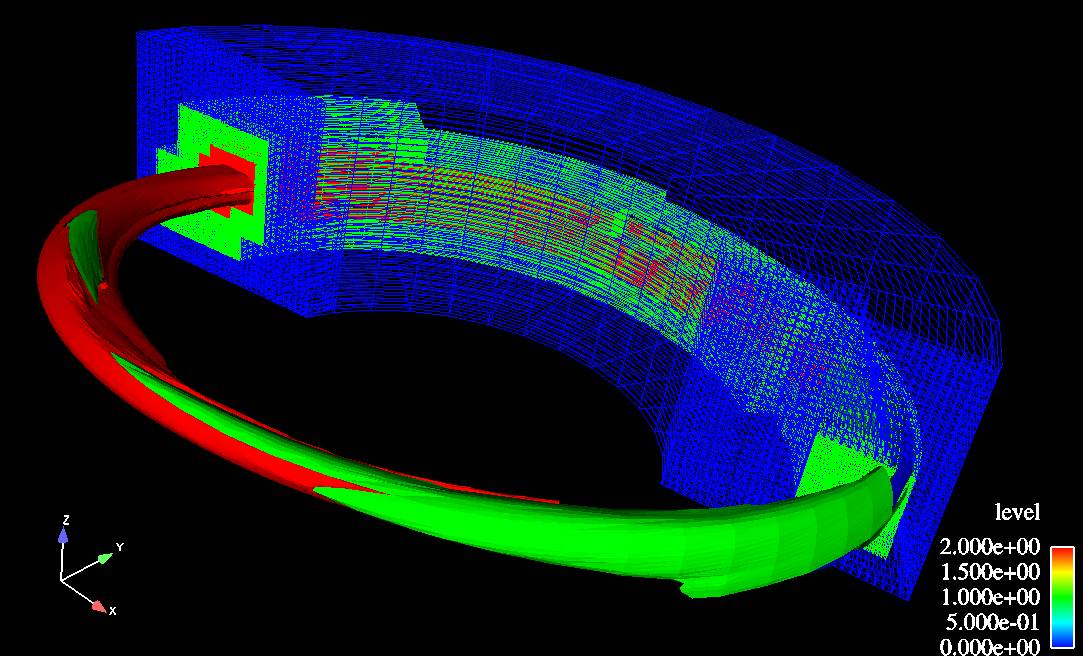
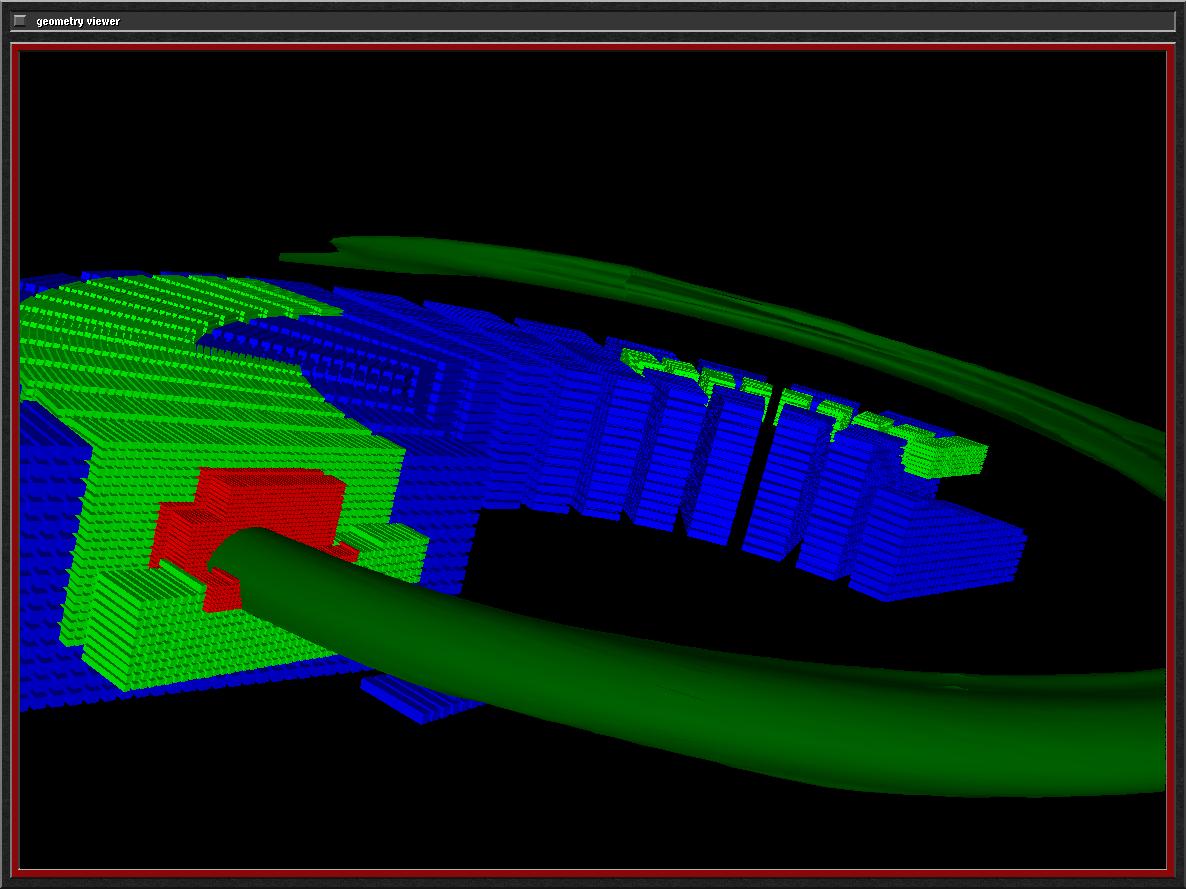
One dataset used in our research is a physics simulation that models the effects of a shock wave passing through an Argon Bubble suspended in air (data courtesy of John Bell and Vince Beckner, LNBL's Center for Computational Sciences and Engineering. The Argon Bubble dataset is defined over a domain of 256 x 256 x 640 cells. Without AMR, a PDE solver would have to compute on 41.9 million grid cells; using AMR, the number is reduced to about 2.9 million (depending on the time step) by building a three-level hierarchy. See Figure 2 for a rendering of this data set and its grid structure. This movie (5.8MB, MPEG-1) shows the first 350 time steps of the simulation, rendered by the single-CPU version of our rendering application.
Due to its hierarchical structure, AMR data poses difficult problems for visualization: Most visualization algorithms assume a uniform grid, and in fact, in the past AMR data has been "flattened out," i.e., resampled to the finest resolution grid, in order to visualize it. The additional resampling effort, and the increase in data set size caused by it, made AMR visualization slow and cumbersome. A visualization program that is aware of an AMR data sets inherent multi-resolution structure, on the other hand, can use this to its advantage. For example, the program could allow to render low-resolution preview images by only considering some of the hierarchy levels. Figure 3 shows three different-resolution renderings of the same data set from (approximately) the same view point.
|
|
|
|
| Figure 3: Rendering AMR data sets at multiple levels of resolution. | ||
The visualization group has developed a number of file format convertors that enable scientists to use a variety of turnkey remote/parallel visualization applications like the LLNL VisIT, CEI Ensight, and AVS Express. This provides APDEC customers a broad variety of data analysis options for understanding Chombo datasets that complement the capabilities of ChomboVis.
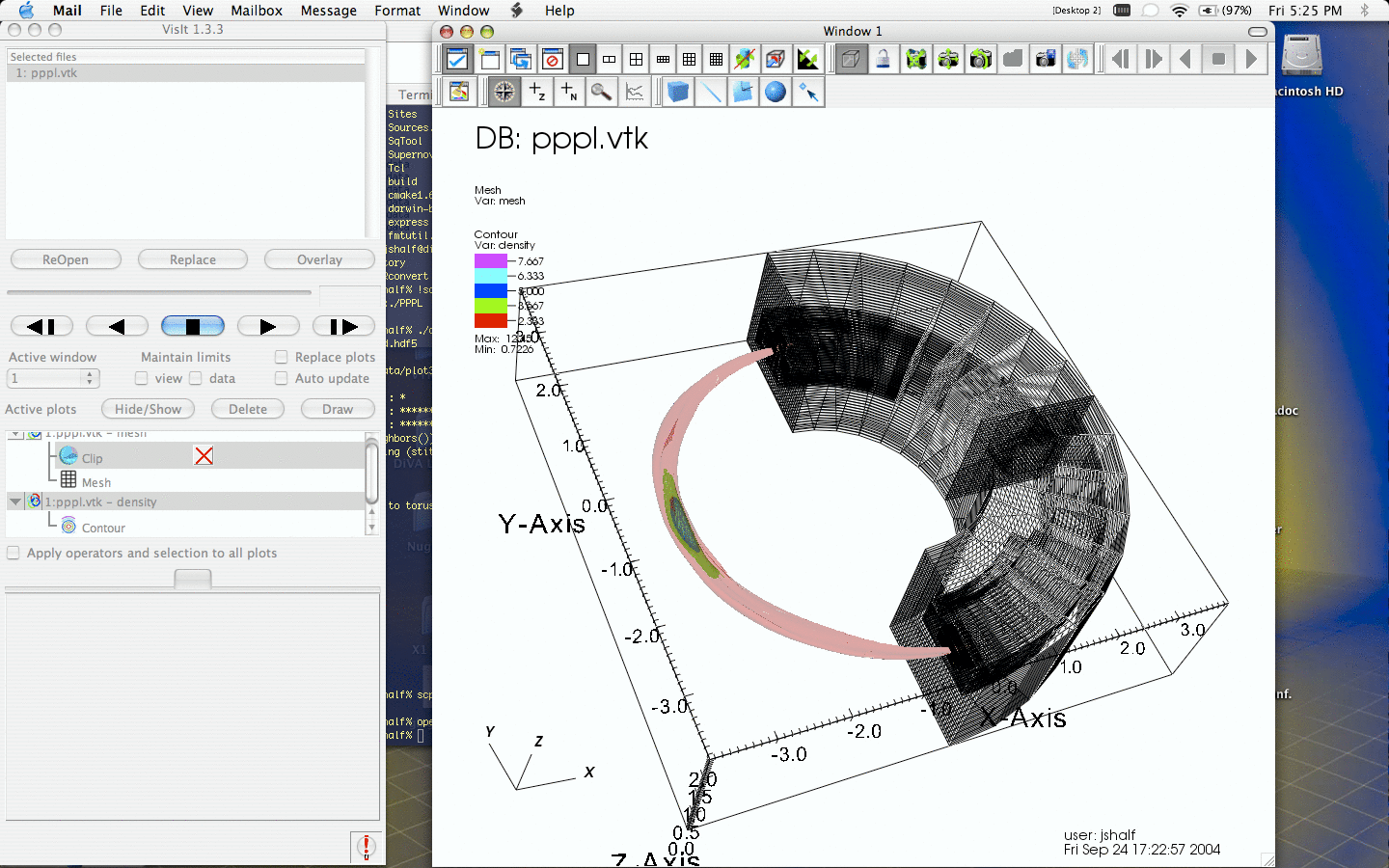
The most computationally and memory efficient way to visualize AMR data is to treat it as a first-class data type and operate directly on its native data structures. Existing off-the-shelf visualization tools and libraries have no concept of native AMR data structures. While new tools like the LBL AMR Volume Renderer, and ChomboVis are taking the first steps towards direct visualization of AMR data structures, it will take many years of development to bring the native AMR visualization algorithms up to the breadth and sophistication of existing tools and frameworks. Some organizations, like PPPL, have come to depend on very sophisticated computational infrastructure built on top of existing tools like AVS/Express, CEI Ensight, and LLNL VisIt.
The visualization group has developed a number of file format convertors that enable scientists to use a variety of turnkey remote/parallel visualizationapplications like the LLNL VisIT, CEI Ensight, VTK, AVS5, and AVS/Express. This provides APDEC customers a broad variety of dataanalysis options for understanding Chombo datasets that complement thecapabilities of ChomboVis. The conversion software converts the grid hierarchy into a hexahedral unstructured mesh. Overlapping cells are removed, and coarse-fine boundaries are stitched in order to minimize rendering artifacts that the boundaries where dangling nodes exist. The tool currently reads the Chomobo HDF5 format and can output data in AVS-UCD, Ensight Gold, and VTK Unstructured file formats (both binary and ASCII form).
While the conversion to hexahedral cells has greatly improved the accessiblity of AMR data, it is not an ideal long-term solution. The hexahedral data representation consumes much more memory than the original AMR data and requires algorithms that are more computationally expensive than those that operate on uniform grids. This limits the effectiveness of this method for larger datasets, but still offers an excellent platform for debugging and data inspection before the AMR code scales up to production data sizes.
The goal of this project is to provide a tool that can render AMR data directly, without the intermediate step through a uniform grid or unstructured mesh representation. This tool should run on a wide variety of machine architectures, and should also be accessible through the internet for remote visualization. Currently, the target architectures include:
|
|
| Figure 4: Overlaying the data domain with an octree. |
Since octree leaves can vary vastly in size, we expect load-balancing problems with this approach. Also, the compositing stage for this distribution method is complicated and involves a lot of communication. On the other hand, the assignment of octree leaves to processing nodes is static and independent of viewing direction, which will reduce I/O overhead during viewpoint animation; furthermore, the increased communication can be overlayed with the rendering itself.
We expect this approach to result in very good load balancing, because the cost of rendering a stretch of cells can be estimated accurately and easily. Also, the compositing step resulting from this distribution is extremely simple, because the partial images can be composited simply in order of processing node numbers. On the other hand, the assignment of cells to processing nodes depends on the viewing direction and might increase I/O overhead during viewpoint animation.
|
|
| Figure 5:Numbering and assigning cells to processing nodes based on viewing direction, in the case of four processing nodes. |
In the program versions for graphics workstations, the rendering of octree leaves is hardware-accelerated. In the current program version, a uniform block of data is uploaded to the graphics hardware as a stack of axis-aligned 2D textures which are then rendered into the frame buffer in back-to-front order using the OpenGL compositing operator. In this way, compositing of partial images is performed implicitly during rendering. Due to the limited precision of the frame buffer (typically 8 bits per pixel and color channel) and the amount of texture slices that are composited, the image quality is lower than in the software-only renderer. Switching to 3D textures and view-orthogonal slices will improve image quality only slightly.
The software-only renderer for supercomputers will be based on a cell projection algorithm. First, we will be using a cell projector with piecewise constant interpolation to show off the hierarchical structure of the rendered AMR data sets; later we will incorporate a higher-quality, piecewise linear cell projector based on work done by Nelson Max.
The compositing strategy needed to combine the partial images generated on each processing node depends on the distribution strategy used. In the second distribution algorithm (back-to-front cell assignment), compositing is trivial: Due to the nature of distribution, all cells rendered by node i are in front of all cells rendered by all lower-numbered nodes, and are behind all cells rendered by all higher-numbered nodes. Thus, the partial images can be composited in order of node numbers, without having to add a depth channel to the transmitted partial images. To do the actual compositing, we will first implement a simple binary-tree compositing step, and maybe later replace that with the more elaborate binary-swap compositing algorithm.
When assigning octree leaves round-robin, compositing is trickier: Each node renders multiple leaves and has to perform multiple compositing operations, requiring to send multiple partial images between nodes. The additional compositing time, however, can be overlayed with the rendering time: A node will render an image, send it off for compositing, render another (small) image and so on. The index of the node that is responsible for compositing the image generated by an (interior) octree node can be determined by its number; therefore, the compositing does not need to send additional messages on top of the partial images themselves. Each node will be running two processes: One will render octree leaves, the other one will wait for partial images from "child" processing nodes, composite them and send them off towards the octree root. Octree leaves are generally traversed in viewing order, so the previously sequential steps of rendering and compositing can now truly be overlayed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}