Visualization Concepts |
This chapter describes the various techniques available for mapping your data into a field.
First and foremost the obvious reason to import data into AVS/Express is because you want to visualize your data. Without data a visualization network is an empty shell.
Most of the visualization modules available in AVS/Express only accept Field objects as input parameters. Hence, if you want to use these modules to visualize your data, you must import your data into a Field object in AVS/Express. For more information on Field objects and Fields in AVS/Express see the Fields chapter in the Visualizing Techniques book.
There are a number of techniques you can use to import your data. Which one you choose will depend on:
This section describes how to map data directly into AVS/Express fields. We begin with this technique because it will help you understand how the data is represented in the field data objects. Often you will be able to use one of the easier methods described in the later sections of this chapter.
The techniques to read the data are discussed starting in Overview of Techniques for Importing Data4-10. First, we will look at how to map arrays into fields.
To get your data into a field, you can import the data directly into a Field structure. To do so, you would need to:
You can see that importing data is often a matter of reading in arrays of data from a data file and storing the array values in the appropriate components of the field. Because of this, you can either:
Since data stored in files often lends itself to being stored in array format, AVS/Express facilitates the process of mapping array data into Field objects with a set of objects called field mappers. Field mappers are objects which take data in one or more arrays as input and output a field, or field component (for example, a mesh), based on the data values.
The inputs to a field mapper are arrays that specify the field components, such as coordinates, node_data, points, and so on. Let's look at a simple example. You have seismic data stored in an ASCII file on disk. The data represents density values at regularly spaced intervals within the measured area. The file consists of three integers indicating the x, y, and z dimensions of the data, followed by the density values, which are stored in float format. The format of this file can be illustrated as follows:
The data in this file easily lends itself to being stored in a field. The dimensions correspond directly to the dims array values of the field. The density values correspond to the field's node_data values. Since there is data for every "point" and no explicit coordinate information, the resultant field is uniform.
Since the field you want to create is uniform and consists of just one component of node data with scalar values, you can use the uniform_scalar_field field mapper to create the field. The uniform_scalar_field mapper (located in the Main.Field_Mappers.Field_Mappers library) takes two input parameters:
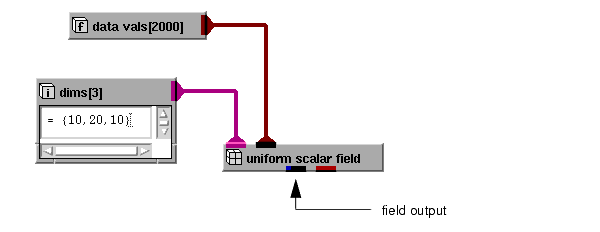
Here is a small network which includes uniform_scalar_field.
The dimensions of the field and its data values are passed in as input and a field is produced as output.
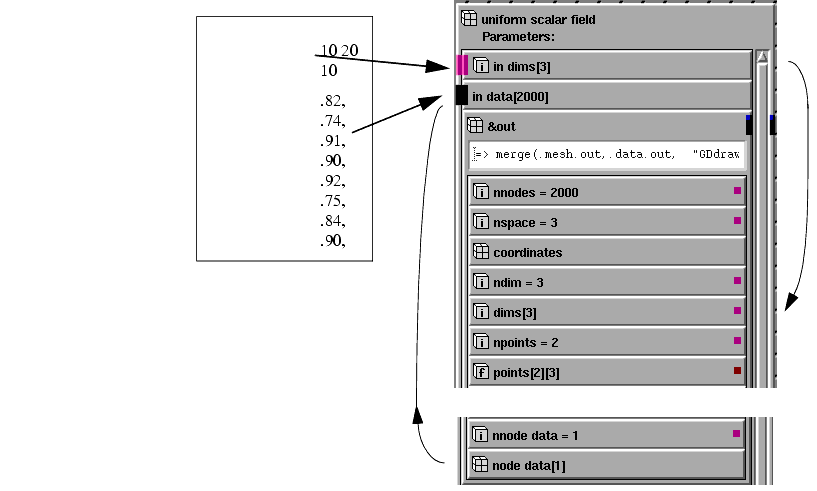
Here is how data in the sample seismic data file format maps to uniform_scalar_field's input parameters and how the mapper's inputs map into a field:
The uniform_scalar_field mapper takes just two input parameters, but it sets all the necessary subobjects in the output field. How does it know how to set the value of subobjects such as ndims and points, which you do not specify as input?
In this example, ndim can be determined from the size of the dims array. The dims array in the example consists of three elements, 10, 20, and 10, so ndim must be three.
But what about points? Since this is a uniform field, the points array will contain just two points which are composed of the minimum and maximum coordinates in the data field. The mapper cannot know what the points should be since you have not specified them, so it assigns reasonable default values. The uniform_scalar_field always sets the minimum point to {0,0} and the maximum point to {dim1-1, dim2-1, dim3-3} (assuming a 3D Field). This means that for our sample data, the maximum point will be {9, 19, 9} since the dims are {10, 20, 10}.
You can always change any of the values in the output field produced by the mapper. If you did not want your field's points to be {{0, 0}, {9, 19, 9}}, you could simply change them to values you prefer. If you always wanted the mapper to produce a field with these different values for points, you could take advantage of the object-oriented nature of AVS/Express and easily create a subclass of the mapper with the different values for points.
There are other mapper objects in the Field_Mappers library which produce more complex fields and allow you to specify other input values. (The Field_Mappers library is found in Main.Field_Mappers.Field_Mappers.) The different mappers produce different kinds of fields. For example, uniform_vector_field creates a uniform field with vector node_data (given dims and a 2D data array). rect_scalar_field creates a rectilinear field with scalar node_data (given dims, points, and a 1D data array).
For more information about field mappers, see the on-line reference pages for uniform_scalar_field, uniform_vector_field, image_field, image_field_rgb, image_field_argb, volume_field, rect_scalar_field, rect_vector_field, struct_scalar_field, struct_vector_field.
As described above, you can use objects in the Field_Mappers sublibrary (Main.Field_Mappers.Field_Mappers) to input data from arrays and output a complete field. But the Field_Mappers library (Main.Field_Mappers) also includes two sublibraries that contain objects that produce just part of a field:
You can use these objects to independently create the different components of a field from different data sources.
To merge the mesh and node data components into a complete field, you can use the objects in another sublibrary in Main.Field_Mappers, the Combiners sublibrary. The Combiners sublibrary also includes objects you can use to combine node_data, and to concatenate or interleave arrays.
Finally, Main.Field_Mappers also includes a sublibrary called Array_Extractors. You can use the objects in this sublibrary to extract a component of an existing field as an array.
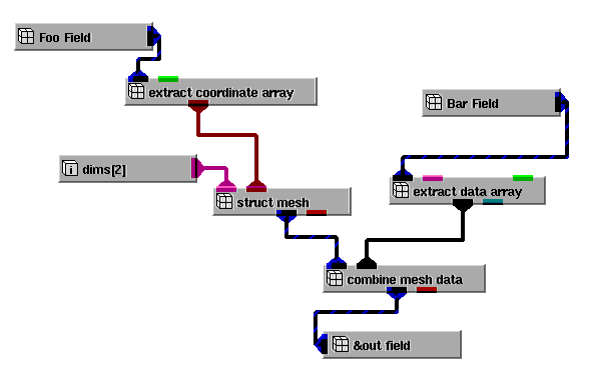
The following network illustrates how combiners and extractors can be used to assemble a field from several different data sources, including other existing fields.
The extract_coordinate_array extractor module gets the coordinates array for the new field from an existing field named "Foo_Field". This coordinates array is then passed into one of the Mesh_Mappers objects, "struct_mesh." The struct_mesh module combines the coordinates array with a dimensions array, "dims", and outputs a mesh. The extract_data_array extractor module gets the node data values for this field from another existing field, "Bar_Field". Finally, the combine_mesh_data combiner module takes the mesh and node data values and merges them together to produce the new field.
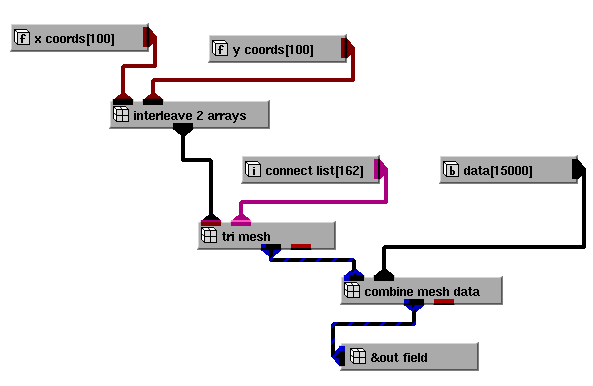
The following network illustrates how you can use combiner objects to merge arrays to create a field.
In this example, another combiner, interleave_2_arrays, takes x and y arrays as input and creates a single array of coordinate pairs (x,y). The Mesh_Mappers module, tri_mesh, creates a mesh from this coordinates input and an array specifying a connection list. Finally, the Combiner module, combine_mesh_data is again used to merge the mesh with an array of node data to produce the complete field.
It is possible to create your own field mappers, tailored to your requirements, using AVS/Express's Object Editor. To create a field mapper, instance a mesh or other field component (from Accessories.FieldSchema) into a module with objects from the Standard Objects library that will be the input parameters. You can then use the Object Editor (accessed using the module's popup menu) to create a custom field, and to set the values of the components of the field to be references to the input parameters.
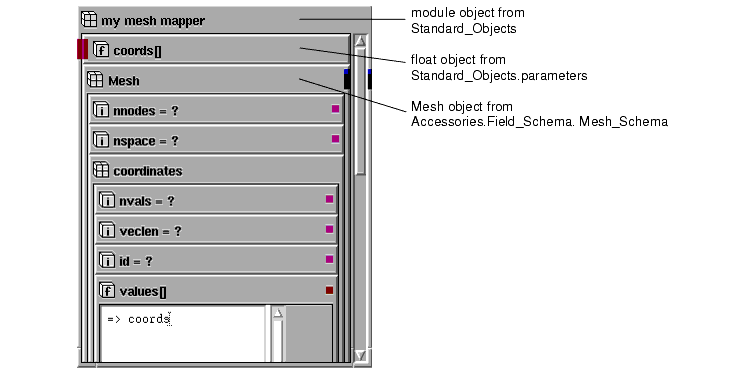
For example, the following module contains a float input parameter and a Mesh field component object:
The Object Editor has been used to rename the float parameter "coords," declare it as an array, and export its input port. In the Mesh object, the Object Editor has been used to display its output port, and to set the values subobject of the coordinates parameter as a reference to the coords input array. The completed mapper takes a coordinate array as input through the coords parameter and outputs a mesh.
Using this same technique, you can extend this simple example to build field mappers that are customized to take your data as inputs and output field components or completed fields.
The field mappers are typically used to read data from a file on disk and map it into a field. There are two objects in AVS/Express which take output produced by a relational database management system (RDBMS) query and map this output data into a field. These are the two table mapper objects, Table_to_Uniform_Field and Table_to_Scatter_Field. The table mappers work like the field mappers, but take arrays of DBcolumn data as input. DBcolumn is the type of data produced by AVS/Express as the result of a database query made using the Database Kit's Query module.
There are many different ways to manipulate the data that you have. With the field or table mapper objects in AVS/Express, there are two main approaches you can use to import your data into a Field object:
Which approach should you use? The answer will depend on the kind of data you have, the format it is in, and the kind of field you need to produce. In general, it is easier to produce fields using mapper objects, so you should use a mapper object whenever possible.
The following table summarizes the basic techniques you can use to import your data into AVS/Express and produce a field. Notice that the techniques are listed in order of complexity, from most simple to most complex. Notice also that the simplest technique is also the least flexible. Using a more complex technique may take longer for you to do, but it will allow you greater control over the resulting Field object. If your data is not stored contiguously in a file and is not easily accessed, writing a reader may be the fastest approach since it gives you the greatest flexibility in accessing the contents of the file.
Each of the techniques listed in the table are described in more detail in the following sections.
If you have stored your data in one of the AVS proprietary file data formats, AVS/Express has a number of reader modules that you can use to import the data. The following table summarizes the reader modules you can use to import specifically formatted data into AVS/Express and produce a field.
For more information on these objects, refer to the online documentation for the reader modules.
netCDF is a standard portable data storage format, widely used in computational science. These macros allow you to store an AVS/Express object including fields or networks in a portable storage format, and also import data in standard netCDF format.
Set the online documentation for the Read_netCDF and Write_netCDF objects for more information.
The Read_Column_File module is used to import ASCII data stored in columns in a file. You can find Read_Column_File on the Main library page in the Data_IO sublibrary.
Many software packages, such as spreadsheets, produce data in this format. You supply the module with the name of the file to read, and some information about its format and which columns you want to read. The module reads the specified file and produces two output parameters containing the data:
A common use for the Data_Array output is to produce simple data in the same format as that returned by the AVS/Express Database Kit's Query module (available in the Developer Edition only). This gives you an easy way to test applications which use data stored in a database without needing to actually query the database. This can be useful if the machine you are working on does not have a connection to the database or if accessing the database can be slow.
The columns of data in the file to be read can be of any data type and they can be separated by a single character, such as a blank or a tab, or by a sequence of characters. You specify the format by setting the input parameters in the Read_Column_File module. Read_Column_File provides a user interface that you can use to specify these values.
The Read_Column_File module produces a field output, in addition to the Data_Array output. The field is a 2D, uniform field with one component of node_data which represents the data read from the columns. The following is a summary of the characteristics of the output field produced by Read_Column_File:
You have a large database containing patient records and are preparing to create a network to visualize some information in the database. You want to look at various visualization modules first, to see what results they produce, and then choose one of those modules to use. Rather than query the database, which may be slow or perhaps even unavailable from your machine, you want to use test data that you have created and stored in a file. The test data looks like this:
The columns are separated by blanks spaces.
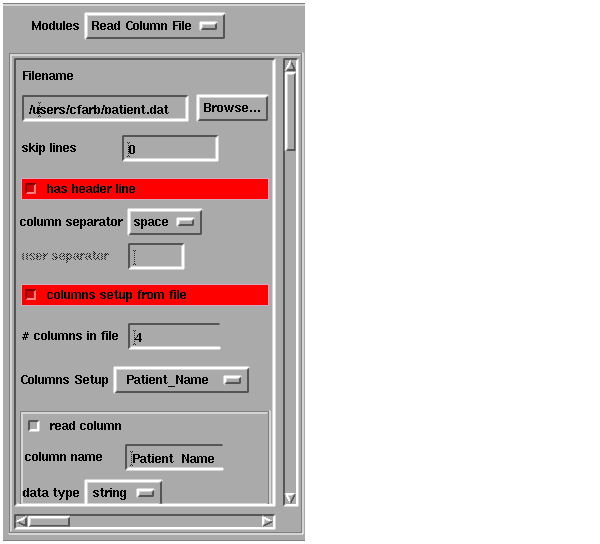
The easiest way to read this data and map it into a field is to use the Read_Column_File module. When you instance Read_Column_File its user interface is automatically added to the Module Panel provided by the viewer or displayed in its own UI shell, as appropriate. The Read_Column_File user interface and the parameter values you set in this example are shown below:
In the user interface, you specify that:
See the online reference page for Read_Column_File for more information on this module and its parameters.
For details of the Field file format and the use of the Read_Field module, see The AVS/Express Field data structure2-2 in this book.
|
|
AVS/Express provides a module called Read_Field in the Main.Data_IO sublibrary that reads files stored in AVS Field file format. This file format consists of an ASCII header which describes the data, followed by the ASCII or binary data, which can be in a separate file. One advantage of this technique is that you can create a header file to describe your existing data without modifying your data files. If you have existing data and can create an AVS Field file header for it, you can take advantage of Read_Field and use it to read your data.
The file's ASCII header consists of a series of lines that describe the characteristics of the field. AVS/Express provides a number of field files in the data/field subdirectory of the AVS/Express install directory. The helens1.fld file, which you will find in this directory, describes a two-dimensional, two-space, uniform field whose dimensions are 327 by 464. Here is what the first part of the header for the field looks like:
Notice that you can include comments in the file; these are indicated by the # character. The helens1.fld file includes the binary data in the same file as the header. To separate the header from the data, two form feed (^L) characters are used.
hydrogen.fld is another data file in the data/field directory. It describes a three-dimensional, uniform volume with byte data. This is the header section of the hydrogen.fld file:
Unlike the helens.fld field file, the data for the hydrogen field is stored in a separate file from the header. You can see a reference to that data file, hydrogen.dat, on the second to last line of the header, followed by the last line, containing the two form feed characters.
Once you have set up your field file, you must then read the data in the file into an AVS/Express Field structure. The Read_Field module does exactly that. The Read_Field module takes the name of the file to read as input and produces a field as output. You can then pass that field into visualization modules.
You can find examples of field files in the data/field subdirectory of the AVS/Express install directory.
If the data you want to visualize is stored in a relational database management system, you can easily import it into an AVS/Express Field using the modules found on the Database Kit library page. (The Database Kit is available only in the Developer Edition of AVS/Express.)
To visualize data stored in a database, follow this basic procedure:
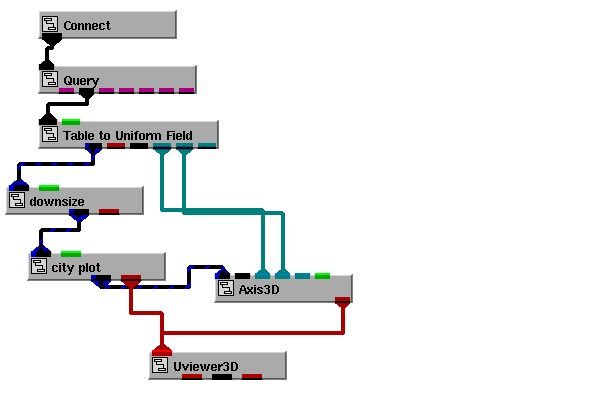
Here is an example of a network that queries data from a database:
The Connect and Query modules display user dialogs that you use to connect to the database and execute a query.
The output of the Query module is an array of DBcolumn objects. DBcolumn is a subclass of Data_Array and is almost identical to it. So, the output of the Query module is quite similar to the output produced by Read_Column_File.
The Database Kit provides easy-to-use interfaces for mapping the DBcolumn array output into a field via the table mapper modules. AVS/Express provides two table mappers, Table_to_Uniform_Field and Table_to_Scatter_Field. As the names suggest, these mappers produce uniform and unstructured (scattered) fields, respectively.
Which of these two mapper objects should you use to map the results of your query into a field? The answer depends partly on what kind of data you have. If your data is sparse, that is, if many columns are missing values, it is generally scatter data and you are likely to use the Table_To_Scatter_Field module. If the records in your database form continuous, uniformly spaced arrays, you are likely to map this into a uniform field. An example of this would be if you have a table in your database containing sales information for every week of the year.
Which mapper you use will also depend on the kind of picture you want to produce. Different visualization modules can require different field types as input. So what kind of field you map the data into will depend in part on which visualization module you want to use.
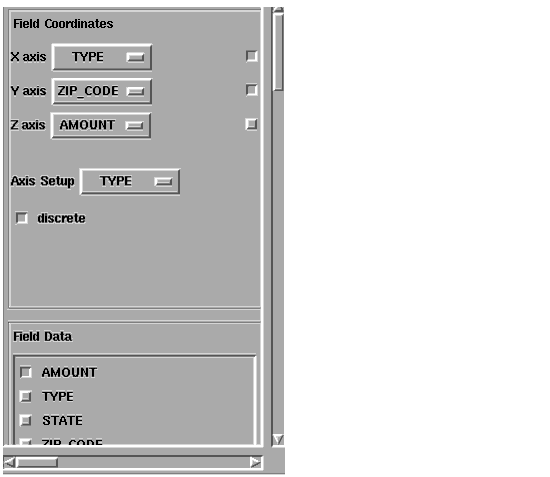
Both of the table mapper modules include a comprehensive user interface. For example, the following illustration shows the interface for table_to_scatter_Field.
You can use the toggles opposite the axes labels (X axis, Y axis, and Z axis) to specify whether you want to include that axis in the field coordinates. For each axis you include, you can use the option menu next to the label to specify the name of the column in the database that you want to use for coordinate values on that axis. You can select one column for the x-axis coordinate values, another column for the y-axis values, and a third column for the z-axis values.
What if your columns do not contain data that function well as coordinate values? For example, suppose you are a sales manager and you want to look at the total sales made for a particular product for each region in your territory for each month of the year. The regions in your territory are organized by postal code. The months are organized by month name, that is, string values. A node with coordinates, {March, 02174} makes little sense. For this reason, you are able to select discrete coordinates. Discrete coordinates enable you to use index values, rather than actual data values. For the months of the year, January would map to 0, February to 1, March to 2, and so on. Discrete coordinates are the default for string data. For numeric data, the default type of coordinates to use is continuous. Continuous coordinates specify that the actual data value be used as the coordinate value, rather than an index.
If you are using continuous rather than discrete data, you can use the Table_to_Uniform_Field interface to bin your data. For each axis of continuous data, you can specify a bin size as a range on the axis. Table_to_Uniform_Field uses the bin size to divide the axis into sub-ranges or bins. The data values that fall into each bin can be analyzed as a group. The default bin size is 1.00.
For example, suppose again that you are a sales manager and you want to look at who is buying your products. In particular, you want to analyze product sales by age group and income bracket. To do this, you can create groups, or bins. For the axis representing ages, you set a bin size of 7 and a Min value of 18 to create age categories from 18-25, 25-32, 32-39, and so on. For the axis representing income levels, you set a bin size of 20,000 to create groups of $0-20,000, $20,000-40,000, $40,000-60,000, and so on. (Data values that fall on a bin boundary are put into the immediately lower bin.) Now you can look at (that is, specify as node_data) the total or average product revenue for the sales that fall into each bin, or you can simply count the number of sales for each bin. This type of analysis is easy to produce using the Table_to_Uniform_Field mapper, and it can be quite useful.
For further information on creating bins, see the on-line reference for Table_to_Uniform_Field.
Now that you have created nodes by specifying the coordinate values, you must now specify what data values to associate with those node locations. These are the node_data values of the field. Since fields can contain multiple sets of values associated with each node (that is, more than one component of node_data), the table mapper module interfaces allow you to select more than one column of data to be used as the node_data values. Each column you select becomes the node_data values for one component of the field's node_data.
Suppose you have a table of sales information with thousands of records in the following format:
The following are some examples of information you can extract and visualize using the Table_to_Uniform_Field mapper.
You want to see the number of sales each salesman has made for certain dollar ranges, 0-5000, 5000-10,000 etc.
You want to see the total number of units sold per week per product.
You want to see the average sales by product, for each salesperson.
In these examples, a Z axis was not used. If it were, a volume would be produced and you would have to pass the output field into a visualization module in order to render it (because the data is not byte data, it cannot be volume rendered in AVS/Express). You can use a module like city_plot to convert your 2-D Field into a 3-D Field. city_plot creates a 3-D bar chart where the height of the bars is determined by the field's data values. Note that in the last example, you would need to specify "normalize" for the data in city_plot's user interface since the amount values are so much larger than the coordinate values (if you did not normalize the data, the bars would be so tall and thin, that you could not see them).
For more information on the city_plot module, see the on-line reference page for city_plot.
AVS/Express provides a sublibrary called File_Access in the Accessories.Utility_Modules library. The File_Access library consists of a set of objects which allow you to describe the format of a file containing your data. The data file can be either ASCII or binary.
The File _Access objects can be divided into two main groups. You can think of one group as being a set of data variables. These objects describe and read actual data.The file_obj object is the general purpose object in this group. It reads scalar or array data from a binary or ASCII file.
The other group of File Access objects work on ASCII files. They do not read data. Instead you use them to extract a portion of the data from a file. That is, you use them to specify or compute an offset into the file so that the next access reads from the appropriate place.
You can use the File Access objects like other objects in AVS/Express by creating the objects and setting the values in them using the Network Editor, or by writing V code. If you want to use the File Access objects this way, consult see the File Objects section of the online documentation or ask for help on one of the objects in the Network Editor
However, there is an easier way to create a group of File Access objects which describe and read a file - the Add File Import Module tool. You launch the Add File Import Module tool by selecting the Add File Import Module... command from the Network Editor's Objects menu. Selecting this command displays the first of a series of dialogs which guide you through the process of creating a set of File Access objects to describe your data file. This group of objects outputs arrays which you can pass into field mappers to map the arrays into a field. Typically, when using the Add File Import Module tool, you will:
For detailed information on using the Add File Import Module dialogs, see the online Help for the tool's windows.
AVS/Express includes some image files in a proprietary format. The format is a simple binary format consisting of two four-byte integers containing the x and y size of the image, followed by pixel data in four-byte tuples. The four bytes represent alpha, red, green, blue (in that order) for each pixel in the image. The pixels are stored in rows, staring with the upper-left pixel in the image. You can picture the file like this:
Before you invoke the Add File Import Module tool to describe the file format, you select the field mapper appropriate for the data. If you look in the Field_Mappers.Field_Mappers library, you will see a mapper perfectly suited to the image file- image_field_argb.
The image_field_argb mapper takes two input parameters: an in_dims array specifying the field's dimensions and an in_data array containing the field's node_data values. This means that the output of the module produced by the Add File Import Module tool should be these two arrays.
Now that you know what outputs your module must produce, you are ready to create it. You first select a library in which to store the module you will create and invoke the Add File Import Module tool from the Objects menu.
Use the dialogs in the Add File Import Module tool to create file variables to represent the two arrays you want to produce for the image_field_argb mapper. The first is the dimensions array. It is an integer array of two elements. The second file variable is the data array. It must be of type byte since the argb tuples are in byte format. What are the dimensions of this data array? You have dim1*dim2 elements in the file and each element contains four bytes of data. So, you specify the dimensions of this data array as [prod(dims)][4], where dims is the name of the dims array you just created.
You have just seen two powerful and useful features of the V language. One is the ability to use built-in functions, such as "prod" in a V statement. The other feature is the ability to dimension arrays based on variable values such as the value of an object. If that value changes, AVS/Express will automatically re-dimension the array.
For further information on programming in V, see the book Using AVS/Express, Chapter 7, "V and the V Command Processor."
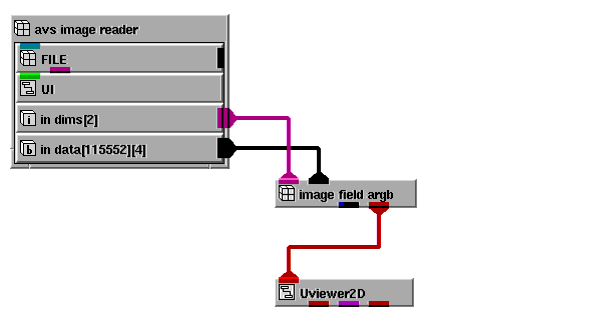
Once you have completed the Add File Import Module tool dialogs, AVS/Express creates a module containing the appropriate File Access objects in the selected library. To use the object, instance it and specify the name of the file to read as the input. The object reads the specified file and returns the output arrays. Connect the two output arrays to the image_field_argb mapper's inputs. The image_field_argb mapper outputs a field and a DataObject (a renderable field). To see the image, connect the DataObject (the red output port) from image_field_argb to a viewer.
Your network will look something like the following:
Sometimes the data you want to visualize is not stored in a file on disk, but is generated in real-time from some live data source. Examples of this might be current stock prices which are acquired hourly, or an application which reads temperatures every 15 minutes.
You can capture and visualize this data using AVS/Express. To do so, you need to fetch the data and store it in a field. There are different approaches you can take to accomplish this. You can:
Which approach you choose depends on your application. Suppose your application tracks the position of an airplane over time. The live data you retrieve gives you the coordinates of the plane's position. With each new set of information, you want to update your display to show the plane's new position. In this case, you would generally replace the values in an existing field (coordinate information in the mesh).
Suppose instead that you want to display the performance of five stocks during the course of a day. Each time you query your stock price generator, you receive the current information about the stocks' prices. In this case, you want to append to a 3D graph tracking the stocks' performance so that you see both the old data and the new. This way, you can watch the stocks' performance change over time. To do this, you append the new data to the appropriate field components (the mesh and the node_data).
If you fetch the new data and store it in a file, you can use the techniques described above to read the new data values in from the file. To do this, you could set up a trigger to execute the module that reads the data whenever new data is available, or you could use a timer to have your module read the file at specified intervals.
How do you access a live data source from within AVS/Express? AVS/Express's Object Manager API provides event handling routines -- the EV routines -- which allow you to add and define event callback handlers. This gives you a mechanism for invoking a particular function when a certain event has occurred, or after a specified amount of time. Using the EV routines you can periodically query your live data source and fetch the new information.
For a summary of the event handling routines, see Chapter 9 of Using AVS/Express and the online documentation for these routines.
This section contains some tips to help diagnose and fix problems that occur in module networks that read data.
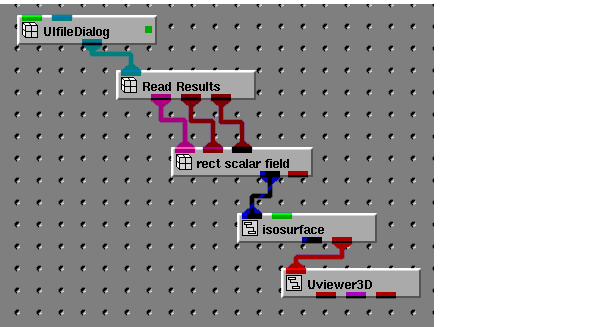
Suppose you have written a reader module which outputs arrays that can be mapped into a rectilinear field. You want to test your new module to see if it produces the results you expect. You set up a network containing your new reader module, Read_Results which looks like this:
The Read_Results module outputs three arrays which are passed into the rect_scalar_field field mapper and the resulting field is connected to the isosurface visualization module. The output of this is passed to a viewer so that you can see the results of the visualization.
Unfortunately, you do not see anything in the viewer, or perhaps you do see a picture, but it is not the picture you expect. What is the problem? It is hard to tell in this network, which is composed of a number of modules. Did your reader produce incorrect outputs or are the outputs correct, but the mapper did not map the arrays into the field as you expected? Your first step is to isolate the source of the problem by verifying each step of the network.
For example, verify your reader objects by examining the arrays or the field they produce before connecting them to another object. Check that:
If you are using a field mapper and your input arrays look good, make sure the field produced by the mapper is what you expect. Remember that to look at the values produced by functions such as get_coords_unif, you can use the $get_array V command. You can also print out the header information and values in a field using the Print_Field module.
If you are having difficulty getting your reader network to work correctly with your data file, try a simpler test case with a smaller data set and/or more regular values. This may enable you to diagnose the source of the problem.
See the Visualization Techniques book for information on how to generate test data.
You may have a reader and have verified that it is producing exactly the right outputs. You pass those outputs into a field mapper and are sure that you have the connections made in the right order. But you get strange results in the viewer. It is possible that are using the wrong field mapper. For example, you may be producing vector data, but are using a scalar field mapper. Make sure you have the right field mapper and if so, check the documentation to make sure that the mapper does what you think it does.
Since the source code for readers involves memory allocation and storage, these routines are prone to memory errors, which can be difficult to track down. If you are getting strange and inconsistent results when you try to read data, it may be due to a memory corruption error. If you have difficulty finding the error, even with a debugger, break your code into pieces and compile and run one piece at a time. For example, if you are producing a structured field, compile and link only the part of the code that reads in the dimensions. Try passing only a dimensions array into the field mapper. Your field will not contain any data values, but you should see the (white) mesh. Once that is working correctly, then try to read the data values in.