Database Kit |
This chapter introduces the AVS/Express Database Kit and explains how to use the Database Kit Modules in an AVS/Express application:
This section is intended for AVS/Express application developers who want to access a supported database from an application and for end users who will be using Database Kit applications.
This section provides the following information:
All users should read the Introduction section and The Design of the Database Kit1-3.
The on-line reference pages for the Database Kit objects are of use primarily to application developers.
This section does not document the following:
Before reading this manual and using this product, you should be familiar with AVS/Express and its components. In particular, you should understand how applications are created from AVS/Express modules and macros. You should also be familiar with the SQL relational database language that is used to access relational databases.
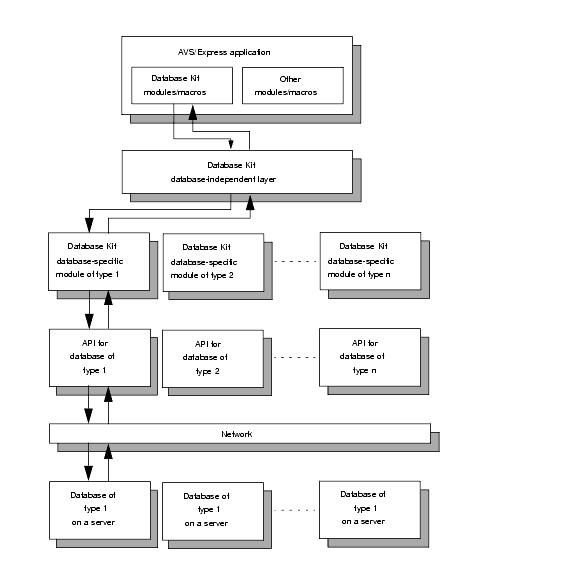
The Database Kit consists of three components: the Database library, the database-independent layer, and a set of database-specific modules.
In many application development environments, an application must communicate directly with various components of the API in order to access a database. This requires the application developer to know SQL and be familiar with the details of the database's API. In the AVS/Express environment, with the Database Kit, developers need to be familiar with SQL, but only need a limited knowledge of the database API.
The following figure illustrates the flow of information from the Database library modules and macros used in an AVS/Express application. It depicts the flow through the database-independent layer and a database-specific module to the database's API and finally to the database installation. (The information flow for the other AVS/Express modules and macros is not shown.)
The Database library contains the AVS/Express modules, macros, and groups that the application developer uses, along with other AVS/Express modules and macros, to build an application that accesses a database supported by the Database Kit.
Most of the Database Kit modules are located in a Database sublibrary called Modules. Each module in this sublibrary performs an SQL or other operation. The following table lists the modules by type and notes their operations.
The remaining Database Kit modules are located in a Database sublibrary called Mappers. The modules map query output to AVS/Express field types.
Three of the Database Kit macros - Connect, Query, and Manipulate - combine one or more Database Kit modules and one or more user interfaces to provide a simplified method of performing an SQL operation. A fourth macro - Tools - incorporates the Connect, Query, and Manipulate macros. These DBmacros are located in two sublibraries. The first set of macros are in the Macro Modules sublibrary, and the second set of macros are in the Macro UI sublibrary. The following table describes these macros.
The remaining Database Kit macros, located in a Database sublibrary called Macro UI, are a subset of the user interfaces used in Connect, Query, and Manipulate; they may be of use to developers building their own SQL macros. The following table describes these macros.
The Database Kit provides two special groups that are used by Database Kit modules.
The database-independent layer is a C-language program that communicates between Database library objects and the database-specific modules.
In the application-to-API direction, the database-independent layer receives requests for SQL operations from the Database library objects in the form of C-language data structures called descriptors and transmits the requests to the appropriate database-specific module.
In the API-to-application direction, it receives messages and other information from a database-specific module, processes them as necessary, and transmits them in the form of descriptors to the Database library objects.
The database-specific modules are a set of routines contained in a single C-language program with multiple entry points. Each entry point corresponds to a supported database type. The modules communicate between the database-independent layer and the database's API.
In the application-to-API direction, the database-specific modules receive requests for SQL operations from the database-independent layer and call the appropriate API routine to perform the operation.
In the API-to-application direction, it receives messages and other information from the API and transmits it to the database-independent layer for further processing.
As noted in the previous section, the Database Kit contains modules, groups, and macros that you can use in AVS/Express applications. Collectively, the Database Kit modules perform SQL operations and some supporting non-SQL operations. Three of the Database Kit macros, Connect, Query, and Manipulate, incorporate one or more of the Database Kit modules that perform SQL operations along with one or more graphical user interfaces that provide fields for user input and for returned values. A fourth macro, Tools, incorporates the Connect, Query, and Manipulate macros. The remaining macros are a subset of the output and other windows used in Connect, Query, and Manipulate.
The Connect, Query, and Manipulate macros incorporate Database Kit modules that perform SQL operations as follows:
When developing an application, you can use the Database Kit modules directly and design your own user interfaces. Alternatively, you can use the Database Kit macros to provide your users with the services of the underlying modules via the included user interfaces.
This chapter provides information about using the Database Kit modules in an application. Where appropriate, this chapter provides references to the Database Kit macros that incorporate these modules. For usage information on the macro interfaces, see Chapter 2, Using the Database Kit Macro Interfaces and see the on-line reference pages for the individual objects.
Many operations performed with the Database Kit require the construction of a SQL statement. Generally, the statement is constructed according to standard SQL usage, that is, it must be a complete SELECT statement that includes all required keywords and all necessary input data values for the statement. In addition, it must meet the following special Database Kit requirements:
If you construct an invalid SQL statement and attempt to process it, the message "DBerror: Invalid statement" is returned to the message parameter of the relevant module. If you entered the statement via the Query or Manipulate macros, the message appears in the Message field and an error window containing additional information is displayed.
When performing an operation on a database, you must have the correct privileges for the database and its contents. If you have insufficient privileges, the operation will fail and the message "DB ERROR: Invalid statement" will be returned.
You must connect to the database server before using a database and you must disconnect from the database server when done.
You use the DBconnect module to perform a connect or disconnect. DBconnect executes an SQL CONNECT or DISCONNECT statement based on user-supplied input and parameter values.
You can also provide connect and disconnect services with the Connect macro. Connect consists of the DBconnect module and a user interface containing input fields in which to supply the required values for the operation and output fields for returned values. You supply values for any other connect/disconnect parameters in the underlying DBconnect module. For usage information, see Using the Connect Interface2-2.
This section summarizes how DBconnect connects to or disconnects from a database. This information may be helpful in determining the source of an error when a connect or disconnect attempt fails.
You can specify the following input values when connecting:
You can specify an input value either explicitly or by using its default value. Default values are established using a group of environment variables provided by the Database Kit, as described in Environment Variables1-14.
When connecting, you must supply, at minimum, the following input values:
A user name is always required for a connect string. Depending on the database type, as indicated by the database driver, one or more of the following may also be required:
Which elements are required and how they are assembled into a connect string are specific to the type of database. For more information, see Connect Strings1-14 or your database documentation.
When disconnecting, you need to supply only the value 1 for the connect_disconnect parameter.
You can use a set of Database Kit environment variables to define defaults for most input values.
When the DBconnect module executes, it reads these environment variables and assigns their values to the corresponding input ports as their defaults. If any of the environment variables are not set, the corresponding input ports have no defaults.
The following table lists the correspondences between environment variables and DBconnect input ports.
There is no environment variable associated with the switch that specifies whether a connect or disconnect is performed. The default is to connect as specified by the value 0 in the DBconnect input port connect_disconnect.
As noted previously, you can supply either a connect string or the elements from which to construct a connect string when you connect to a database. The format of a connect string is database specific. In addition, connect strings can vary depending on how the database driver has been installed, what networking component(s) is used, where the associated server resides, and so forth. See your database administrator to obtain a valid connect string.
As a reference, Chapter 3, Database-Specific Usage provides some database-specific information on connect string format. Alternatively, see your database documentation.
The DBConnect macro's user interface includes a text entry field for the user's password. In past AVS/Express releases, the password was echoed when it should have been suppressed. The AVS/Express user interface does not support this text suppression feature, so the default behavior has been changed in the DB.V file so that the echoed characters are white and therefore not visible.
You use the DBquery module to query a database. To perform a query, DBquery executes a SQL SELECT statement followed by one or more fetches of the returned data. Additional user-supplied values control how the query is performed; for example, the amount of data fetched at one time or the total number of data rows returned by the query. For more information, see The Query Operation1-18.
You can cancel a query with DBcancel, if your database supports the cancellation of queries on your operating system platform.
You can also provide query services with the Query macro. Query consists of the DBquery module and a user interface containing input fields in which to supply the required values for the operation and output fields for returned values. You supply values for any other query parameters in the underlying DBquery module. For a reference description, see Using the Query Interface2-8.
You use DBquery module to query a database as follows:
During this process, you can view additional information as necessary.
The next section describes how the Database Kit stores and processes query output. Subsequent sections describe various aspects of the query operation.
Before using the DBquery module to query a database, it is useful to understand how the Database Kit stores and processes data. Discussions of database operations typically describe operations as being performed on rows of data. While this is true, it does not reflect the underlying structure of the Database Kit and, in some cases, the database server with which the Database Kit communicates.
Depending on the database being queried, the database server may return data to the Database Kit in either rows or columns. Regardless of how the database server returns the data, the Database Kit stores it in columns. The columns of data are made available to the application in an array of DBcolumn objects. DBcolumn is a Database Kit group that consists of the following:
For more information on DBcolumn, see the on-line reference page.
Although the Database Kit stores data as columns, data is frequently described as occurring in rows, where a row consists of the same-indexed entries in a set of column arrays. For example, the third row of a set of data stored as a set of column arrays would consist of the following:
This definition of row is important for making sure you are utilizing the same view of the data as this manual. Therefore, keep this definition of "row" in mind as you use this manual.
DBquery selects data from a table or view in the current database based on specifications in the SQL SELECT statement and returns the data as an array of columns, one for each column specified by the SELECT statement.
DBquery executes as a select operation followed by a fetch operation. The select operation involves sending the SELECT statement to the database server which returns the data. The fetch operation moves the data into an array called column_array[], where it is accessible.
A fetch operation executes as follows:
If there are more rows to be returned and auto-fetch mode is on (see Disabling and Enabling Auto-Fetch1-21), DBquery repeats the fetch operation as specified by the DBquery parameters until either it reaches the number of rows specified by userbuf_row_limit or it has returned all the rows. When the user buffers are full, DBquery either flushes the buffers and begins a new fetch operation or ends the query, as determined by the status of the flush_when_full parameter (see Flushing the User Buffers1-20).
The data in the user buffer is returned to the application in an array of type DBcolumn. For information on viewing the returned query data, see Viewing Query Output1-28.
This section discusses a number of programming considerations that you should review before using the DBquery module in an application. Several of these discussions focus on particular services provided by one or more of the DBquery parameters. Not all parameters are described here; for a full list and descriptions, see the on-line reference page for DBquery.
This section does not discuss error handling; see Handling Errors1-52 instead.
By design, DBquery does not execute a fetch operation as soon as an SQL SELECT statement has been entered. This ensures that you can set query parameter values before the query begins. To trigger execution of the query, you use the process_statement parameter. By default, process_statement is set to 0 (do not execute) and must be set to 1 to initiate execution.
DBquery provides three parameters that you can use to control the size of the fetch and user buffers used during fetch processing: rows_per_fetch, userbuf_realloc_interval, and userbuf_row_limit.
The size of the fetch buffers is specified by rows_per_fetch; by extension, this parameter also controls the number of rows returned by each database fetch. The initial size of the user buffers is specified by userbuf_realloc_interval; this value also specifies the number of rows to be allocated whenever more rows are required. The maximum size of the user buffers and, by extension, the total number of rows returned by DBquery are specified by userbuf_row_limit.
These values interact as follows:
You should select values for these parameters carefully because your choices will affect how memory is used during the fetch processing used to return the results of a query. You should be especially careful when setting these values if your system or the systems of the users of your Database Kit application have limited memory available.
One way to use less memory is to set a small value for rows_per_fetch. Decreasing the size of the fetch buffer will result in more frequent fetches but smaller memory usage. In particular, do not set the value of rows_per_fetch near or equal to the value of userbuf_row_limit unless you have set the flush flag (see Flushing the User Buffers) and are deliberately working with small user buffers.
Also, you should not initially allocate the entire number of rows required for the user buffers; that is, you should not set the value of userbuf_realloc_interval near or equal to the value of userbuf_row_limit. Instead, set userbuf_realloc_interval to a low number to ensure that memory is used in small quantities as it is needed.
A number of memory usage status fields that allow users to gauge memory usage for a query are returned to the application in DBquery's output_statistics parameter. This information can be made available to users; for an example, see The Query Statistics Window2-36. You should be aware that these fields include only the memory allocated explicitly by the Database Kit; they do not include the memory allocated by the database-native routines.
As noted previously, DBquery executes fetch operations as specified by the DBquery parameters until either it reaches the number of rows specified by userbuf_row_limit or it has returned all the rows. When the user buffers are full, DBquery either flushes the buffers and begins a new fetch operation or ends the query, as determined by the status of the flush_when_full parameter (also called the flush flag). This section provides some notes on the operation and use of flush_when_full.
When flush_when_full is set to 1 (TRUE), newly fetched data is written starting at the first entry in the user buffers if there is no room to append it to the end of the user buffers. This is the default behavior and happens automatically and without further warning; therefore, the application must be designed to ensure that existing user buffer data can be summated, moved, or otherwise processed before it is flushed. To do this, the application must check continually to see if the following condition is true before performing another fetch operation:
If this statement is true, the data in the user buffers should be processed, after which another fetch operation can be performed. (The number of user buffer rows used is returned to the application in the userbuf_rows_used subobject of DBquery's output_statistics parameter.)
When flush_when_full is set to 0 (FALSE), the query terminates if there is no room to append the fetched data to the end of the user buffers. This termination is treated as a normal end of operation and no error message is returned.
By default, fetch processing operates in a mode called auto-fetch; that is, it fetches repeatedly until it returns the number of rows specified by userbuf_row_limit to the application or it has returned all the rows. DBquery provides a switch called loop (see loop in the on-line reference page for DBquery) that turns auto-fetch on or off. When you turn auto-fetch off, fetch processing pauses between fetch operations. This is useful for viewing partial results. With auto-fetch turned off, the value of the process_statement must be reset to 1 after every pause to continue fetch processing.
For more information on the flush flag, see Flushing the User Buffers1-20.
You cannot cancel a query directly from DBquery. You must use the DBcancel module instead. For more information, see the on-line reference page for DBcancel. The DBquery cancel_button parameter allows you to trigger execution of a DBcancel module and cancel the query.
DBcancel will attempt to cancel any select or fetch operation currently running on the server and will prohibit further fetches for the current query. In addition, it will release all memory allocated for the query by the Database Kit or the database software.
A database typically supports different datatypes than does the Database Kit. Therefore, the Database Kit must map the data returned by a query into its own datatypes. The Database Kit supports the following datatypes:
The database-independent layer typically determines the mapping to be used; however, you have some control in the mapping of numeric fields.
In general, the database-independent layer maps numeric types as follows:
For information on your database's supported datatypes and for supported limits for scale, precision, and number of digits in the result, see your database documentation.
You can use the numeric datatype specifier parameters- Force output, Float type, and Fixed type- to override the database-independent layer's default mapping of numeric fields. You must exercise care when using these parameters to override the database-independent layer's mapping. If the mapping you select causes an overflow condition, fetch errors resulting in cancellation of the current query will occur. For specifics beyond this section see The Query Output Types Window2-34
DBquery provides numeric datatype specifier parameters that you can use to override the database-independent layer's default mapping of numeric fields: use_floating_type_only, floating_type, and fixed_type. You must exercise care when using these parameters to override the database-independent layer's mapping. If the mapping you select causes an overflow condition, fetch errors resulting in cancellation of the current query will occur and the error message "DB ERROR: Recoverable database error" will be returned.
The three override parameters are as follows:
When you are displaying the output from a query in a UIwindow, you must be able to represent null-value fields in a recognizable way. This is not, however, an issue for string fields, which use a zero-length null-terminated string. It is an issue for numeric fields (byte, signed short integer, signed integer, unsigned integer, float, or double float), because all possible entries in a numeric field have value, including 0.
DBquery provides the following parameters for specifying how null values are represented in numeric and string fields:
null_value_byte
null_value_short
null_value_int
null_value_uint
null_value_float
null_value_double
For each, you provide an integer value that will be inserted into null fields of that datatype. The default is -127 for null_value_byte and -999 for the others.
As mentioned in The Query Operation1-18, the Database Kit's database independent layer creates fetch buffers and user buffers during fetch processing. In addition, the DB Kit creates several other buffers that you may find useful in certain circumstances. For example, a buffer called fetchind contains information about indicators for null fields. This information is useful for determining when a null substitution value has coincided with recognizable data.
This section describes all the buffers created by the DB Kit during fetch processing. The buffers created by the database-independent layer are implemented as arrays of column data.
Each SQL SELECT statement returns one or more columns and/or select-list items. For example:
During fetch processing, the Database Kit provides as many fetch, user, and other buffers as there are columns described in the SQL SELECT statement. For example, if the statement describes three columns, the Database Kit provides three fetch buffers, three user buffers, and so on.
The following Database Kit buffers are of interest to application developers:
The database-specific modules were built using the call-level interface for the relevant databases. For some database engines, the Database Kit copies the fetchret, fetchind and fetchsize buffers directly from the arrays used by the database's call-level interface and does not modify them. For other database engines, these buffer types are not all directly supported or are used in different ways by the native database call-level interface. Wherever possible, data is collected and deposited in these buffers to present a common, database-independent interface for presenting row-level information at the fetch level. For more information, see Chapter 3, Database-Specific Usage.
As noted previously, the data in these extra arrays is useful in cases where a null substitution value might coincide with recognizable data. For example, in the absence of the fetchind buffer, if a null substitution value of 0 was used, it would not be immediately apparent whether a null or a 0 was returned.
To access the relevant data, you might set up an outside loop using the DBquery module and then, after each fetch operation, interrogate the fetchind buffer to find out whether a column value was specifically a null. Alternatively, you might set up an inside loop and set the user buffers to the same number of rows as the fetch buffers (that is, userbuf_row_limit = rows_per_fetch) with the flush_when_full flag set. You could then query these buffers in conjunction with userbuf data contents rather than accessing the fetch buffer directly (although they are, in this case, exact copies of one another).
DBquery provides a set of statistics about the current query that you can make available to users in a UIwindow. This information is available in the subobjects of the output_statistics parameter:
You can use the StatisticsUI macro, which uses the output_statistics parameter, to display output statistics for users. For an example, see The Query Statistics Window2-36.
A user may have more than one connection in operation at a time. DBquery provides a set of information about the current connect that you can make available to users in a UIwindow. This information is available in the subobjects of the connect_information parameter:
The connect_information parameter is of type DBconnectInformation. For more information, see the on-line help.
You can use the ConnectionUI macro, which uses the connect_information parameter, to display connection information to users. For an example, see The Connection Information Window2-40.
As noted previously, the data returned from a query is stored in an array of DBcolumn, each DBcolumn group of which consists of the following:
For a description of the DBcolumn group, see the on-line help.
You can view the returned query data in either of two ways:
To display the data in table form in an output window, input it to an OutputWindowUI macro (see the on-line help). This macro provides a UIwindow called Output Window, which displays query output. The Query macro incorporates the OutputWindowUI macro into its user interface; for more information, see Using the Manipulate Interface2-21 or The Output Window2-38.
Alternatively, you can construct your own output window using the UIwindow macro; see Creating an Integrated Application Interface1-21 for more information.
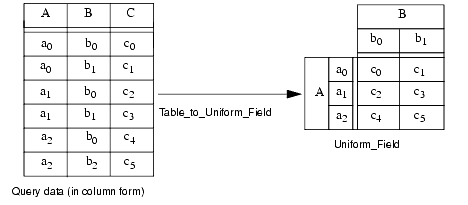
You can visualize query data in AVS/Express but you must first map it from the array of DBcolumn objects in which it is stored to an AVS/Express field type. To perform the mapping, you use the Database Kit's Table_to_Uniform_Field and Table_to_Scatter_Field mapper modules to map it to a uniform field or to a scattered field (an unstructured field that can store scattered data). Once you have done this, you can visualize the resulting uniform or scattered field in AVS/Express.
Table_to_Uniform_Field and Table_to_Scatter_Field perform different mappings, as follows:
For descriptions of the modules, see the on-line help for Table_to_Uniform_Field and Table_to_Scatter_Field. For information on AVS/Express field types, see the AVS/Express Visualization Techniques manual.
Query execution can now be broken down into four stages and various results generated by each stage can be reused. By using DBprepareStatement, DBexecuteStatement, DBdefine, and DBfetch together in this order, they serve the same purpose as DBquery. Please note that DBexecuteStatement needs to be executed before DBdefine!
Prepares the user issued SQL statement.
This group needs a valid connection handle passed down from DBconnect, whose interface was not modified. It retrieves the connection information from the handle and a valid "select" statement from the user, then creates a statement handle once process_statement is set to 1.
This will be a local operation only, no server round-trip required. If successful, a valid statement handle will be created and passed downstream. Otherwise, NULL value will be passed as the pointer. In either case, status will be updated, message will be displayed. Attribute done will be set to 1 to indicate end of processing only when executed successfully.
The other attributes contained in this group are analogous to their counter-parts in DBquery. Please consult the documentation on DBquery for details.
Executes the prepared SQL statement
This group will send the query to server for execution. Upon returning, information regarding select list items will be available. No prefetching is done because we don't know the select list item types before execution. Thus, no user buffer can be appropriately defined first, a requirement for prefetching.
When invoked, the DBexecuteStatement group will first verify that a valid connection is available and a valid statement handle exists. It then passes the statement handle to the server for execution once process_statement is set to 1.
Upon successful execution, a statement handle with the description of select list items will be passed downstream. Otherwise, NULL is assigned. Attribute done will be set to 1 to indicate end of processing only when executed successfully.
The other attributes contained in this group are analogous to their counter-parts in DBquery. Please consult the documentation on DBquery for details.
Defines user buffers for data returned by the query.
DBdefine receives the select list description, determines returning data type and allocates user buffers accordingly to retrieve n rows of data where n is "rows_per_fetch".
Validation of connection and statement handle is the first task. If valid, the module queries the statement handle for parameters describing each select list item for their name and internal type. For each parameter, appropriate sized user buffers are allocated for retrieval. If either the connection handle or the statement handle is NULL and process_statement is set, this module will display an error message. If the statement handle has not been "executed", an appropriate error message will also be displayed.
The other attributes contained in this group are analogous to their counter-parts in DBquery. Please consult the documentation on DBquery for details.
Retrieves data returned by SQL query into allocated user buffers.
DBfetch uses the user buffers allocated during the define stage to issue fetch commands against the appropriate database server. Data will then be copied from temporary buffers to columns and null_indicators array. Space for these arrays are expanded once the existing buffer is filled in accordance with "userbuf_realloc_interval" attribute which must be a multiple of initial user buffer size (i.e., "rows_per_fetch").
The connection and statement handle is first verified. If either the connection handle or the statement handle is NULL and process_statement is set, this module will display an error message. If the statement handle has not been defined, an appropriate error message will be displayed.
The other attributes contained in this group are analogous to their counter-parts in DBquery. Please consult the documentation on DBquery for details.
DBquery selects data from a table in the current database based on user specifications and returns it to the user.
DBquery selects data from a table in the current database based on user specifications and returns it to the user. The data are selected based on the SQL SELECT statement that is entered into the statement input port. It is returned as an array of columns, one for each column specified by the SELECT statement. The columns in the array are of type DBcolumn (see DBcolumn) which is itself an array.
Regardless of how returned data are stored, a number of the parameters used to control query processing refer to "rows" of data; for example, userbuf_row_limit. A data row is a logical structure that concatenates the same-indexed entries in an array of columns. For example, the third "row" of a set of columns would consist of the third item in the first column concatenated with the third item in the second column, and so forth. When a parameter specifies a number of rows, it is, in fact, referring to the number of items in a column.
DBquery executes as a select operation followed by a fetch operation. The select operation involves sending the SELECT statement to the database server, which returns the data. The fetch operation moves the data into column_array[], where it is accessible to the user.
A fetch operation executes as follows:
If there are more rows to be returned and auto-fetch mode is on (see next paragraph), DBquery repeats the fetch operation as specified by the DBquery parameters until either it reaches the number of rows specified by userbuf_row_limit or it has returned all the rows.
DBquery auto-fetches by default. When auto-fetching, it performs the additional fetch operations without pausing for user action between them. You can turn auto-fetch off with the loop parameter. With auto-fetch off, DBquery pauses for user action between fetch loops, and the user must reset process_statement to 1 to resume fetch processing.
You can choose to restart execution of the SELECT statement from the beginning at any time with the new_statement parameter.
Changing query control parameters, such as fetch buffer size, in the middle of a query, is only possible when auto-fetch is off. The change will be ignored and only take effect for the next query.
Also note that DBquery now has its update method called query . This could cause reference errors in any applications with an object called "query" that is not directly referenced (for example =>query , rather than =><-.<-.query ).
The integration between MS Developer Studio and AVS/Express has been updated and expanded, allowing you to build, link, and debug Express applications using DevStudio. See the on-line reference pages for a complete description.
It is now possible to specify that objects marked as invisible (using the object's Visible flag) be ignored when determining the extent of graphics objects in normalizing or determining a new center for scaling and rotation.
The Camera has a new integer object, named "norm_invisible", which acts as a simple toggle. When non-zero, invisible objects are used in computing extents. When zero, only visible objects will be taken into account. The default is non-zero (1).
When this value is changed, if there are invisible objects, the picture will change between the object normalized and centered with the invisible object used to calculate extents, and without.
You use the following modules to modify row data in a table:
These modules operate in the same fashion; that is, they send a DELETE, INSERT, or UPDATE statement, respectively, to the database.The database server performs the specified SQL operation and returns indicators of success or failure including error messages where appropriate. All three of these modules provide the same parameters. For reference descriptions of these modules, see the on-line reference pages for DBdelete, DBinsert, and DBupdate.
You can also provide delete, insert, and update services with the Manipulate macro. Manipulate consists of DBdelete, DBinsert, DBupdate, and other modules, and a user interface containing input fields in which to supply the required values for the operation and output fields for returned values. You supply values for any other parameters in the underlying modules. For more information, see Using the Manipulate Interface2-21.
You use the DBdelete, DBinsert, or DBupdate module to modify data rows in a database as follows:
During this process, you can view various types of additional information as necessary.
This section discusses a number of programming considerations that you should review before using the DBdelete, DBinsert, and DBupdate modules in an application. These discussions may include services provided by one or more of the DBdelete, DBinsert, and DBupdate parameters. Not all parameters are described here; for a full list and descriptions, see the on-line reference pages for DBdelete, DBinsert, and DBupdate.
This section does not discuss error handling; see Handling Errors1-52 instead.
By design, DBdelete, DBinsert, and DBupdate do not execute a delete, insert, or update as soon as the relevant SQL statement has been entered. To trigger execution of the delete, insert, or update, you use the process_statement parameter. By default, process_statement is set to 0 (do not execute); set it to 1 to initiate execution.
Delete, insert, and update operations start a transaction if one has not already been started. Some databases require that you end the current transaction (for example, from a previous query) before starting a delete, insert, or update operation; see your database documentation for specifics.
The modifications made by a delete, insert, or update to a database are temporary until you end the current transaction. You can end a transaction either by committing it (making the changes permanent) or rolling it back (aborting the changes). The DBcommit and DBrollback modules perform these operations; see Ending Transactions1-47.
A user may have more than one connection in operation at a time. DBdelete, DBinsert, and DBupdate provide a set of information about the current connect that you can make available to users in a UIwindow. This information is available from the connect_information parameter, and consists of the following:
The connect_information parameter is of type DBconnectInformation. For more information, see the on-line help.
You can use the ConnectionUI macro, which uses the connect_information parameter, to display connection information to users. For an example, see The Connection Information Window2-40.
You use the DBmiscStatement module to perform miscellaneous SQL operations via a specified SQL statement. The database server performs the specified SQL operation and returns indicators of success or failure, including error messages where appropriate. This module provides the same parameters as DBdelete, DBinsert, and DB update. For a reference description of this module, see the on-line help.
You can also provide delete, insert, and update services with the Manipulate macro. Manipulate consists of an assortment of Database Kit modules and a user interface containing input fields in which to supply the required values for the operation and output fields for returned values. You supply values for any other parameters in the underlying modules. For a reference description, see Using the Manipulate Interface2-21.
You use the DBmiscStatement module to perform miscellaneous SQL operations as follows:
During this process, you can view various types of additional information as necessary.
This section discusses a number of programming considerations that you should review before using the DBmiscStatement modules in an application. These discussions may include services provided by one or more of the DBmiscStatement parameters. Not all parameters are described here; for a full list and descriptions, see the on-line help.
This section does not discuss error handling; see Handling Errors1-52 instead.
By design, DBmiscStatement does not perform the specified SQL operation as soon as the SQL statement has been entered. To trigger execution of the operation, you use the process_statement parameter. By default, process_statement is set to 0 (do not execute); set it to 1 to initiate execution.
Miscellaneous SQL operations may start a transaction if one has not already been started. Some databases require that you end the current transaction (for example, from a previous query) before beginning an operation that starts another transaction; see your database documentation for specifics.
If the miscellaneous SQL operation starts a transaction, the modifications that it makes to the database are temporary until you end the current transaction. You can end a transaction either by committing it (making the changes permanent) or rolling it back (aborting the changes). The DBcommit and DBrollback modules perform these operations; see Ending Transactions1-47.
A user may have more than one connection in operation at a time. DBmiscStatement provides a set of information about the current connect that you can make available to users in a UIwindow. This information is available from the connect_information parameter, and consists of the following:
The connect_information parameter is of type DBconnectInformation. For more information, see the on-line help.
You can use the ConnectionUI macro, which uses the connect_information parameter, to display connection information to users. For an example, see The Connection Information Window2-40.
You use the DBcommit and DBrollback modules to end transactions. These modules send a SQL COMMIT or ROLLBACK statement, respectively, to the database.The database server commits or rolls back the current transaction and returns indicators of success or failure, including error messages where appropriate. (The current transaction includes all commands executed on the current connection.) The modules also have the same set of parameters, which are used in a similar fashion by each. For reference descriptions of these modules, see the on-line reference pages for DBcommit and DBrollback.
You can also commit and roll back transactions with the Manipulate macro. Manipulate consists of DBcommit, DBrollback, and other modules, and a user interface containing input fields in which to supply the required values for the operation and output fields for returned values. You supply values for any other parameters in the underlying modules. For a reference description, see Using the Manipulate Interface2-21.
This section discusses a number of programming considerations that you should review before using the DBcommit and DBrollback modules in an application. These discussions include services provided by one or more of the DBquery parameters. Not all parameters are described here; for a full list and descriptions, see the on-line reference pages for DBcommit and DBrollback.
This section does not discuss error handling; see Handling Errors1-52 instead.
By design, DBcommit and DBrollback do not execute a commit or a rollback immediately. To trigger execution of the commit or rollback, you use the process_commit or process_rollback parameter. By default, process_commit and process_rollback are set to 0 (do not execute); set them 1 to initiate execution.
A user may have more than one connection in operation at a time. DBcommit and DBrollback provide a set of information about the current connect that you can make available to users in a UIwindow. This information is available from the connect_information parameter, and consists of the following:
The connect_information parameter is of type DBconnectInformation. For more information, see the on-line reference pages for DBconnectInformation.
You can use the ConnectionUI macro, which uses the connect_information parameter, to display connection information to users. For an example, see The Connection Information Window2-40.
The Database Kit provides modules that perform three types of support operations, as follows:
These modules do not perform SQL operations and, therefore, do not use the database-independent layer of the Database Kit.
This section provides usage information and programming considerations for DBload, DBappendStatement, DBlist, and DBsave. The remaining module, DBerrorString, is typically used in error handling and is discussed in Handling Errors1-52, instead.
SQL statements are frequently so long that typing them into the statement field of a Database Kit module is very time consuming. In addition, if you enter a long and complex SQL statement by hand you run the risk of introducing typographical errors that can cause the statement to return incorrect information or fail. The Database Kit provides the DBload and DBappendStatement to assist in constructing SQL statements.
For reference descriptions of these modules, see the on-line reference pages for DBload and DBappendStatement.
The Database Kit provides two modules that manage query output: DBlist and DBsave.
For reference descriptions of these modules, see the DBlist, DBsave, DBappendStatement, and DBload on-line reference pages.
This section discusses programming considerations that you should review before using DBappendStatement, DBlist, DBload, or DBsave in an application. These discussions include services provided by one or more of their parameters. Not all parameters are described here; for a full list and descriptions, see the DBlist, DBsave, DBappendStatement, and DBload on-line reference pages.
This section does not discuss error handling; see Handling Errors1-52.
By design, DBappendStatement, DBload, and DBsave do not execute as soon as the required input has been entered. To trigger execution of the operation, you use the process, process_load, or process_save parameter, respectively. By default, the parameter is set to 0 (do not execute); set it to 1 to initiate execution.
Two sets of messages and codes provide Database Kit applications with error information:
The returned messages and codes reflect either the success or the failure of an operation.
Error offset information may also be available for those SQL errors resulting from invalid SQL statements. This information indicates the offset of the error; that is, the position within the SQL statement where the error occurred. Whether this information is available is database dependent; see your database documentation.
Database Kit messages and codes are returned to an application by the database-independent layer in a Database Kit connection descriptor. These messages and codes are available to an application in the message and return_code parameters, respectively, of the following Database Kit modules:
The returned Database Kit messages and codes reflect either the success or the failure of an operation.
A code of 0 indicates success. The message associated with a code of 0 varies depending upon the module and state of execution; for example, Connected or Not connected, to indicate the connection state of the module. A nonzero code indicates failure.
Chapter 4, Database Kit Messages and Codes, describes the Database Kit messages and codes. Messages that indicate failure have additional information that suggests one or more actions to take.
You can make the Database Kit messages and codes available to users in a user interface. For an example, see Using the Query Interface2-8.
A short message may also be available. In general, a message of this type complements the main status code returned by the Database Kit and identifies conditions of which the user should be aware that are not always returned as part of the SQL error message (see the next section) or that are reported by the database independent layer. For example, a query of an Oracle database might return one of the following subsidiary messages:
SQL messages and codes originate with the database server processing an SQL operation for the Database Kit. There are two types of SQL errors:
Errors of the first type are returned to an application by the database-independent layer in a Database Kit connection descriptor. These messages and codes are available to an application in the db_specific_error_message and db_specific_error_code parameters, respectively, of the following Database Kit modules:
The returned Database Kit messages and codes reflect either the success or the failure of an operation. A code of 0 indicates success and a nonzero code indicates failure.
The SQL messages and codes returned to the db_specific_error_message and db_specific_error_code parameters are specific to SQL and reflect only SQL-specific information, as follows:
If a Database Kit error reflects an underlying SQL error and you cannot obtain enough information about the error from the Database Kit message, obtain the SQL return code and error message and then see your database documentation.
You can make these SQL messages and codes available to users in a user interface. See Chapter 2, Using the Database Kit Macro Interfaces
Row-level errors are returned in the fetchret buffer. For more information, see Using Fetch-Processing Arrays1-25.
When the database server returns an SQL message and code that indicate an invalid SQL statement, it may also return the error offset: the position where the error occurred, measured as the number of bytes from the beginning of the statement. Whether this information is available is database dependent; see your database documentation.
If error-offset information is returned, it is available to an application in the statement_error_offset parameter of the DBquery modules.
The value returned to statement_error_offset is intended to be used as input to the DBerrorString module, to provide additional error information to the user.
The DBerrorString module inserts a marker into an input string at a specified position. An example of the marker is shown below:
The DBerrorString module is intended primarily for creating an error-location string showing where an error occurred in an invalid SQL statement. You must provide information to the module's input ports as follows:
DBerrorString returns to the error_string output port a string consisting of the SQL statement with the marker inserted at the position denoted by the error offset. You can use an additional returned value, valid_error, as a trigger to open a UIwindow in which the error string is displayed.
For a reference description of this module, see the on-line reference page for DBerrorString. For an example of a UIwindow that contains this type of information, see The Error Window2-42 in Chapter 2, Using the Database Kit Macro Interfaces.