Index
Problem Description
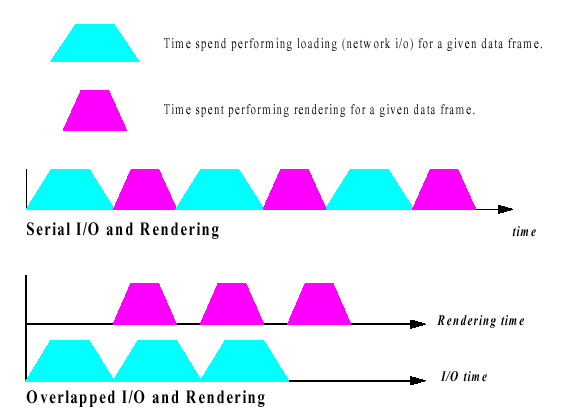
The following figure shows two timing diagrams, each depicting the amount of time spent during I/O and rendering in the Visapult back end. I/O loading time is shown in cyan, and rendering time is shown in magenta.
In the serial case, I/O occurs first, followed by rendering. The topmost timing diagram shows the cumulative elapsed time required when these two tasks occur in a serial fashion. However, when these tasks are overlapped, the second timing diagram shows how rendering for frame N begins at the time data is loaded for frame N+1. As long as the time for rendering is less than the time for I/O, the network pipe will be kept completely full.
Approach
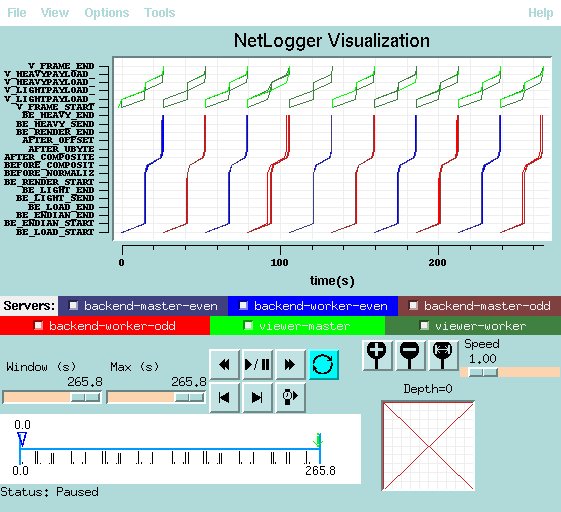
Prior to this overlapping I/O and rendering, disk or network I/O and volume rendering was a serial pipeline in the Visapult backend. As the first figure below shows, all of one time step's worth of data must have been completely processed (read in, rendered then the results transmitted to the viewer) prior to any work being performed on the next time step.
However, once I/O and rendering are overlapped in the back end, we can begin I/O of the next time step while rendering the current time step. The following figure illustrates this overlap. Alternating time steps (even, odd) have been colored with red and blue so they are easy to tell apart. Note how I/O for frame 2 starts while rendering is occuring in frame 1.
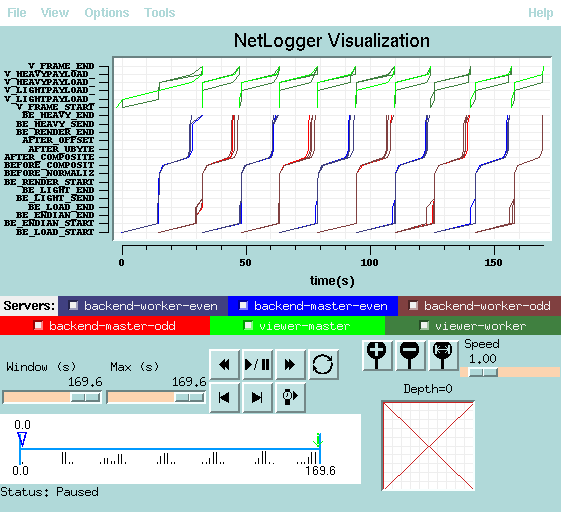
In this example, we are reading 160MBytes per time step from the DPSS. It takes approximately 15 seconds to move the data from the DPSS into host memory for rendering. Rendering takes approximately 10 seconds (4x336Mhz UltraSparc-II processors). The total time required in non-overlapped mode is about 265 seconds (10 time steps), whereas the total time required for overlapped processing is about 170 seconds, a speedup of about 55% (which accurately reflects the "imbalance" ratio of time spent rendering vs. time spent doing i/o, 10 secs. vs. 15 secs, a 50% difference).
Comparison of Performance on Two SGI Platforms
The following images show the performance profile of a Visapult run performed on two different SGI platforms at LBL/NERSC. The first platform, judgedee.lbl.gov, is connected to the LBL DPSS via a gigabit ethernet link. Over this link, it takes approximately 6 seconds to load a single time step, or 160Mbytes, for an effective bandwidth rate of about 200 Mbps. The performance of overlapped and non-overlapped processing are shown below.
In contrast, escher.nersc.gov and the DPSS are connected via a 100Mbps link. Over this link, it takes 25 seconds to move 160Mbytes of data, for an effective bandwidth rate of about 50Mbps.
To emphasize the importance of the network bandwidth requirements posed by an application that performs scientific visualization of large scientific datasets, we used 8 processors on escher (4 for rendering, 4 for I/O), while we only used 4 on judgedee (2 for rendering, 2 for I/O).
| Host | Overlapped Rendering and I/O | Non-overlapped Rendering and I/O |
|---|---|---|
| Judgedee | 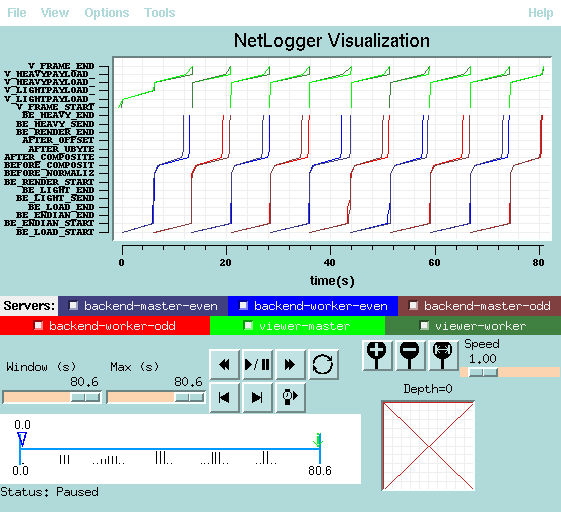 |
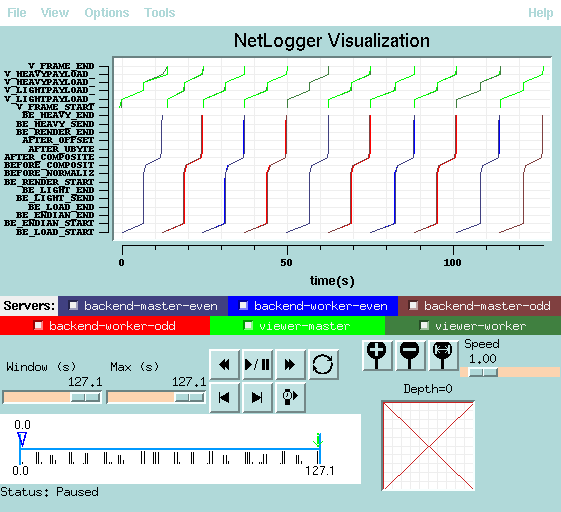 |
| Escher | 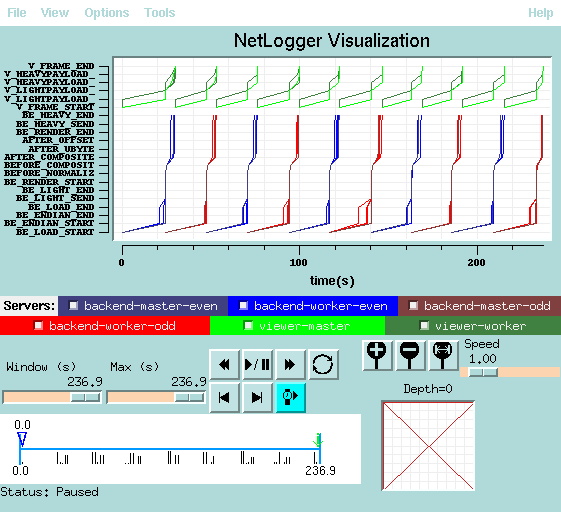 |
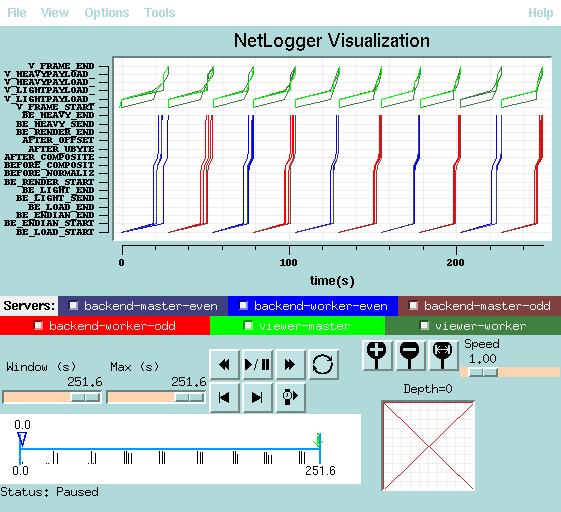 |
Technical Info and Implementation Details
As stated elsewhere, the Visapult backend is a parallel program built using MPI. To implement the overlapped I/O and rendering, we extended the backend so that each MPI process launches a detached pthread. The detached thread is responsible for reading data, while the MPI process is responsible for managing and synchronizing the reader thread, and for rendering data while the thread is reading data.
Each backend MPI process and pthread synchronize using a pair of SystemV semaphores. One semaphore is used to release the pthread, so that it will read the next timestep's worth of data. The other semaphore is used to signal that the pthread has completed the read operation. Since the MPI process and the pthread share a memory address space, additional control variables, such as which timestep to read, grid size, open file descriptor, and so forth, are placed into a structure which is visible to both.