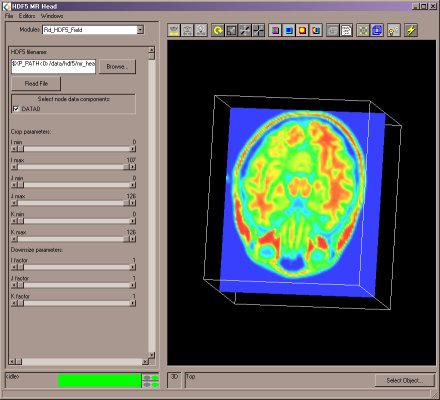
The handling of large data sets has been greatly improved with the addition a field reader and writer based on the HDF5 library. HDF5 (Hierarchical Data Format) can be used to store large amounts of data. The new HDF5 based reader and writer is intended as a successor for MODS.Read_Field and MODS.Read_UCD (.fld and .inp files respectively). The data models for these older formats are not an exact match to AVS/Express fields. The new HDF5 based format has been explicitly designed around AVS/Express fields and allows the user to have data files that take advantage of virtually all the features of AVS/Express fields. Additionally, this format can represent both structured and unstructured fields, thus providing a single unified file format. This will reduce learning time and enhance opportunities for software reuse.
AVS/Express takes advantage of HDF5's abilities to select subsets of the data file. The reader has an integrated crop and downsize facility. This dramatically reduces the amount of memory required by allowing the user to select a subset of the data before it is read in. The reader can also be configured to only read selected node data components and selected cell data components, effectively giving the area an integrated extract_component and extract_cell_component.
For more information about HDF5, HDF5 documentation and HDF5 tools and utility programs can be found at http://hdf.ncsa.uiuc.edu/HDF5/.
You may load in your data into AVS/Express through preexisting means and then write out HDF5 format using the new write macros/modules. However, to import a dataset that is in a new format, you may wish to write a translator from the new format to AVS/Express-compatible HDF5. To do this, you will need to download your own copy of the HDF5 library and documentation. Example source code is provided with AVS/Express to help you get started.
There are 4 new high level Macros:
There are 7 new low level Modules: